My Journey Through the AbbVie Data Scientist Interview


Overall, I felt like AbbVie really emphasizes the integration of "technical skills + pharma scenarios"—just grinding through LeetCode-style problems isn't very helpful. Case interviews can trip you up if you don't have a solid grasp of biostatistics and FDA regulations.
Round 1: Basic Skills Screening
1.Implement the core logic of logistic regression in Python (without using libraries), and explain the iterative process of gradient descent.
2.Explain the difference between p-value and confidence interval, with an example from a clinical trial application.
What are 3 methods for handling missing data, and which one is most recommended for a patient dataset? Why?
3.How would you use an A/B test to validate the effects of adjusting the dosage for a certain drug? What variables need to be controlled?
Round 2: Coding
1.Compare the pros and cons of random forest vs. XGBoost when predicting drug efficacy.
2.Write a SQL query to find patient IDs from the patient_treatment table who have had adherence rates < 60% for 3 consecutive months.
3.Explain what overfitting is, and how to avoid it when modeling medical data? Give a specific regularization method as an example.
4.How would you use a time series model (like ARIMA) to forecast monthly sales of a biologic drug?
I have to say,Linkjob.ai is seriously handy AI Interview tool —it gives real-time AI reference answers, and even if they ask you to share your entire screen, the interviewer won't see you're using it.
Round 3: Case Interview
Given clinical trial data for a certain oncology drug (including biomarkers, age, treatment duration, etc.), design a model to predict patient response (CR/PR/SD/PD). What feature engineering should you consider?
When analyzing real-world evidence (RWE) data, how do you handle confounding variables? Give 2 statistical methods as examples.
Implement Kaplan-Meier survival analysis in Python, and explain the logic for handling censored data.
Round 4: Business Depth Assessment
1.Explain the FDA's statistical requirements for clinical trial data, and how to ensure model results comply with regulatory standards?
2.How would you quantify the safety vs. efficacy trade-off for a drug? What metrics would you need?
3.Design a dashboard to monitor quality metrics for drug manufacturing. What key indicators should it include?
Finally, here are some prep tips from me:
1.Don't underestimate experience from small companies or projects—the key is being able to articulate "how you thought through it."
2.In healthcare, they value your patience, communication skills, and data sensitivity way more than whether you know transformers inside out.
3.The pharma industry is still ramping up data talent hires right now—compared to tech, the stability is leagues ahead...

AbbVie Data Scientist Interview Experience
Here's a quick overview of AbbVie's core business areas:
Immunology: Treatments for rheumatoid arthritis, psoriasis, and inflammatory bowel disease
Oncology: Targeted therapies and immunotherapies for hematologic malignancies and solid tumors
Neuroscience: Treatments for Parkinson's disease, migraine, and psychiatric disorders
Eye Care: Dry eye syndrome, glaucoma, and retinal diseases Aesthetics: Medical aesthetics products and treatment solutions
Question 1: Clinical Trial Endpoint Analysis
Interviewer: "We have a Phase III clinical trial for our new rheumatoid arthritis drug. The primary endpoint is ACR20 response at week 12. However, we're seeing heterogeneous treatment effects across different patient subgroups. How would you approach identifying predictive biomarkers for treatment response?"
My approach at the time was as follows.
First, I would conduct a comprehensive subgroup analysis, stratifying patients by their demographics, disease severity, and existing biomarkers. This would allow us to preliminarily identify which patient groups respond better to treatment.
Next, I would adopt a machine learning approach, using Random Forest to pinpoint key features—since it excels at handling high-dimensional data and provides feature importance rankings—while simultaneously applying LASSO regression for feature selection to avoid overfitting.
For statistical validation, I'd pay close attention to multiple testing corrections, employing the Benjamini-Hochberg method to control the false discovery rate, and using bootstrapping to compute confidence intervals for assessing result stability.
Most importantly, I'd collaborate closely with rheumatologists to interpret the biological relevance of the identified biomarkers, ensuring our findings are not only statistically significant but also clinically meaningful.
The interviewer followed up: “How would you handle the multiple testing problem when analyzing dozens of potential biomarkers?”
My response was: When dealing with dozens of potential biomarkers, I'd use a hierarchical testing approach—first stratifying them based on biological prior knowledge, prioritizing those with strong theoretical support for initial testing, then moving on to the exploratory ones. At the same time, I'd apply the Benjamini-Hochberg procedure to control the false discovery rate by adjusting p-values, which is more powerful than the traditional Bonferroni correction and particularly well-suited to biomarker discovery scenarios.
Question 2: Real-World Evidence Analysis
The interviewer asked: "We want to understand the real-world effectiveness of our oncology drug compared to the standard of care, using a claims database. What are the key challenges, and how would you address them?"
My analytical approach at the time unfolded as follows:
First, I recognized that the biggest challenge in real-world evidence analysis is selection bias, since in the real world, the reasons patients receive different treatments are often tied to their prognosis. To address this, I would use propensity score matching to control for confounding variables, by pairing patients with similar characteristics who received different treatments to create comparable groups.
Second, there's the issue of immortal time bias, which is particularly common in oncology studies because patients must survive long enough to receive certain treatments. I'd tackle this with landmark analysis or time-dependent covariates.
For the challenge of missing data, I'd employ multiple imputation methods—not just straightforward statistical imputation, but one informed by clinical expertise to ensure the imputed values are medically plausible.
Finally, on outcome definition, I'd collaborate closely with oncologists to establish clinically meaningful endpoints, such as progression-free survival or quality-adjusted life years, rather than relying solely on simple mortality metrics.

Case Study Presentation: "Optimizing Clinical Trial Design"
The case I selected: "How to Use Historical Control Data to Reduce Placebo Arm Size in Rare Disease Trials"
Background:
AbbVie is developing a drug to treat a rare genetic disorder. Traditional RCTs require a large number of placebo patients, but recruiting patients for rare diseases is extremely challenging.
My Approach:
My overall approach is to establish a comprehensive framework for integrating historical control data. First, in terms of historical data integration, I would systematically collect placebo arm data from all similar trials conducted in the past five years—not only primary endpoints, but also patient demographics, disease characteristics, concomitant medications, and other relevant information. I would then develop rigorous data quality assessment criteria to evaluate the usability and comparability of each historical study.
In terms of statistical methodology, I would adopt a Bayesian approach to combine historical and concurrent controls, specifically using the power prior method to adjust the weighting of historical data. This weighting would be dynamically adjusted based on the similarity between the historical data and the current study, while also conducting robust sensitivity analyses to account for potential population drift over time.
For the regulatory strategy, I am well aware of the FDA's specific guidance on historical controls, so I would engage in a pre-submission meeting with the FDA during the study design phase to discuss our methodology and ensure regulatory acceptance. Additionally, I would incorporate an adaptive design to allow for mid-trial adjustments—for instance, if the historical controls prove insufficiently comparable, we could increase the sample size of the concurrent control arm.
Finally, for the implementation plan, I would first conduct a pilot study to validate our methodology, ensuring that all stakeholders—including the clinical team, regulatory affairs, and biostatistics team—share a common understanding of the approach. I would also establish comprehensive risk mitigation strategies to address any potential challenges.
Challenging Questions from the Q&A Session:
"How would you validate that historical controls are truly comparable?"
"What's your contingency plan if the FDA doesn't accept the approach?"
"How do you balance statistical efficiency with regulatory acceptance?"
Question: Precision Medicine Algorithm
Interviewer: "We want to develop a precision medicine algorithm for our oncology portfolio. Given a patient's genomic profile, clinical characteristics, and treatment history, how would you recommend the optimal therapy sequence?"
My design approach at the time was as follows: I would build a comprehensive multi-modal prediction system.
For processing genomic data, I would focus on actionable mutations and known drug targets, using variant annotation tools to identify clinically relevant mutations, followed by pathway analysis to understand their functional impact.
For clinical characteristics, I would standardize all features—including demographics, performance status, comorbidities, and lab values—while applying appropriate encoding methods for categorical variables.
Handling treatment history is particularly crucial, as responses and toxicities from prior treatments can significantly influence future selections; I would create features that capture not only which treatments were used, but also response duration, toxicity profiles, and resistance patterns.
In terms of model architecture, I would employ an ensemble approach, training separate models for each available treatment to predict both efficacy and toxicity—since these outcomes are equally important but may exhibit different predictive patterns. I'd leverage gradient boosting methods like XGBoost for structured data, while incorporating deep learning techniques for genomic data processing.
Most critically, I'd design the utility function to balance efficacy and safety considerations, potentially using a weighted scoring system where the efficacy score minus the weighted toxicity score generates an overall utility score for each treatment option.
To ensure clinical applicability, I'd incorporate uncertainty quantification, employing techniques like conformal prediction to provide confidence intervals for predictions, allowing clinicians to gauge the reliability of recommendations. I'd also build in explainability features, using SHAP values to clarify why certain treatments are recommended for specific patients—a key factor for clinical adoption.
Question: Clinical Data Integration
Interviewer: "We have clinical trial data, real-world evidence, and genomic databases. How would you create a unified data platform for drug development decision-making?"
My architecture design approach is to build a scalable and secure data platform that can handle heterogeneous data sources while maintaining data quality and compliance.
First, at the data storage layer, I would use AWS S3 as a data lake to store raw data from various sources, since it can manage structured, semi-structured, and unstructured data while offering cost-effective storage for large genomic datasets. I'd implement data partitioning strategies based on study type, therapeutic area, and data collection date to optimize query performance.
At the data processing layer, I'd use Apache Airflow to orchestrate complex ETL pipelines, which can manage dependencies between processing steps while providing monitoring and error-handling capabilities. Each data source would have a dedicated processing pipeline with tailored data quality validation rules—for instance, clinical trial data would be checked for protocol deviations, real-world evidence would be validated for consistency in coding systems, and genomic data would undergo quality control for sequencing metrics.
To enable machine learning applications, I'd establish a feature store using tools like Feast, which would provide consistent feature definitions across projects, facilitate feature reuse, and maintain feature lineage for reproducibility. I'd also implement automated feature engineering pipelines to generate derived features, such as treatment response indicators, biomarker combinations, and temporal patterns.
At the ML platform layer, I'd integrate MLflow for experiment tracking, model versioning, and deployment, allowing data scientists to easily compare approaches, reproduce results, and deploy models to production. I'd also implement an A/B testing framework to evaluate model performance in real-world settings.
For the visualization and access layer, I'd use Tableau to create interactive dashboards tailored to different stakeholders—patient-level insights for clinical teams, population-level summaries for regulatory teams, and portfolio-level analytics for business teams. Finally, I'd implement role-based access control to ensure data security and compliance with regulations like HIPAA.
Tips for AbbVie Interviews
Research AbbVie
Before my abbvie data science interview, I always take time to learn about the company. I want to understand what abbvie stands for and what values matter most to them. Here’s how I approach my research:
I read abbvie’s mission and values to see how my own goals match theirs.
I look for recent news or projects involving abbvie, especially those related to data.
I prepare for behavioral questions by using the STAR method, so my answers stay clear and focused.
I review the job description and think about how my skills fit the role.
I check which data tools and technologies abbvie uses, so I can talk about them during the interview.
Show Teamwork
Abbvie values teamwork, I use the STAR method to explain my role and the results. I talk about how I communicate and solve problems together, even if the experience comes from a volunteer project or a different job.
Manage Stress
Long interviews can feel stressful, especially during a data science interview panel. I use a few tricks to stay calm:
I organize my tasks with tools like Trello.
I set priorities using simple methods
I take short breaks before the interview.
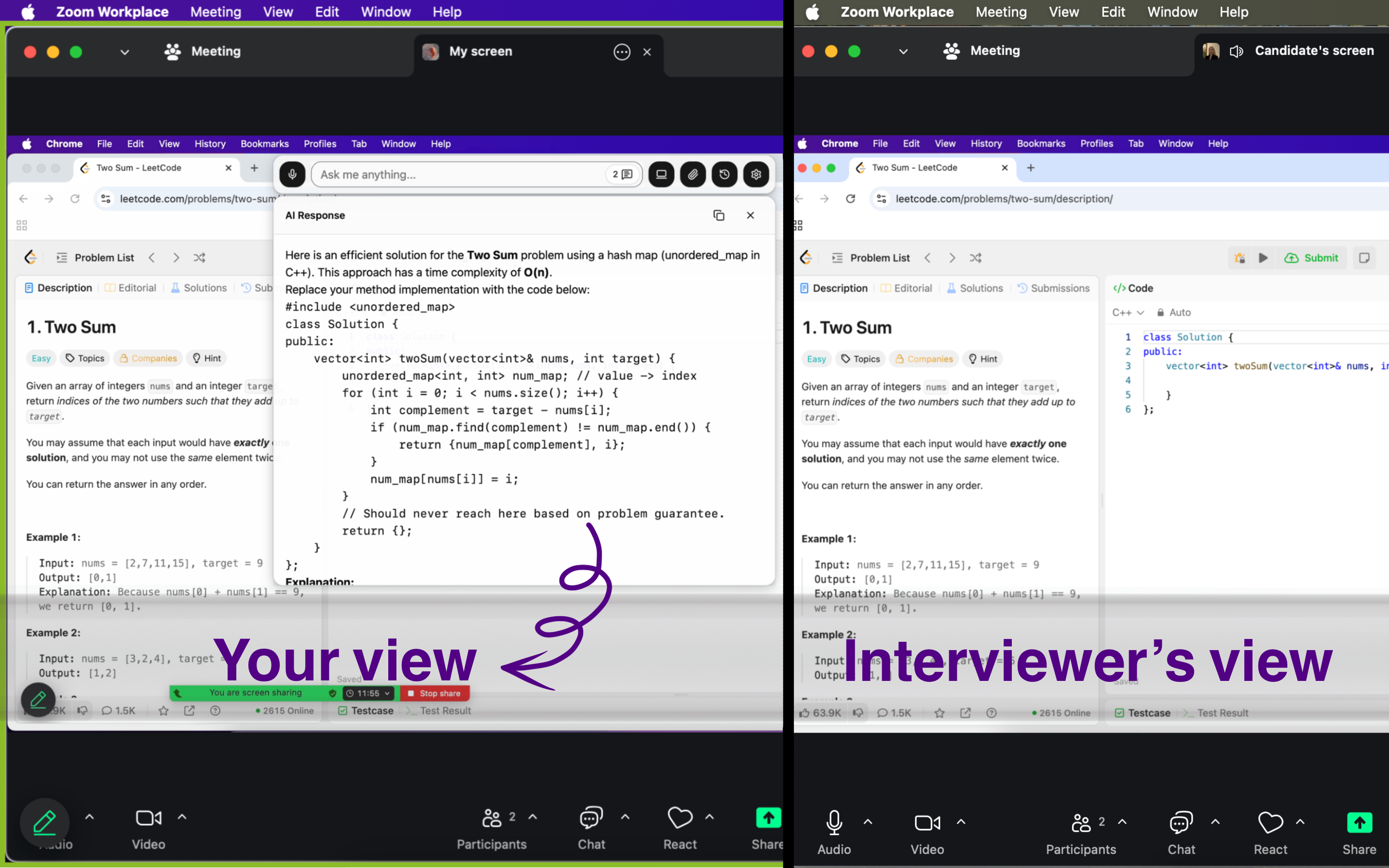
To be absolutely safe, I tested Linkjob.ai in advance with my friends. The current AI is indeed very powerful and can provide great help to people. The main purpose of my test was to ensure that the other party's computer screen really couldn't see that I was using AI.
Stay persistent and keep learning. You’ve got this!
FAQ
What should I focus on when preparing for the AbbVie interview?
I always focus on the job description. I review my technical skills and I also research AbbVie’s recent work.
How do I handle technical questions if I get stuck?
Just use Linkjob.ai directly.I personally think that passing the test is more important than anything else.
Does AbbVie value teamwork during the interview?
Yes, teamwork matters a lot.
How soon should I follow up after my AbbVie interview?
I send a thank-you email within 24 hours. I mention something specific from the interview. This shows I care about the opportunity and respect AbbVie’s process.
See Also
Navigating the Databricks New Graduate Interview Journey in 2025
A Comprehensive Guide to the OpenAI Interview Experience in 2025
Insights from My Anthropic Software Engineer Interview in 2025
Reflections on My Initial Week with an AI Interview Tool
My Preparation Journey for the Generative AI Interview in 2025

© Copyright 2025 Linkjob.ai - All Rights Reserved.