My 2026 xAI Interview: All Questions From Every Stage & Rounds


XAI Grok Interview Requirements and Process
The XAI interview requires candidates to possess traditional machine learning skills, as well as experience in large-scale distributed systems, deep learning optimization capabilities, and a profound understanding of cutting-edge AI research.
My interview process included four rounds: algorithms, system design, ML basics, and live coding. There was also an online assessment at the start of the process.
I am really grateful to Linkjob.ai for helping me pass my interview, and that’s also why I’m sharing here my entire interview experience and the questions I encountered. Having an undetectable live AI interview assistant during the interview indeed provides a significant edge.
In the following sections, I’ll go over each stage of my interview in detail and share the questions I encountered along the way.
XAI Interview Stages and Rounds
Resume Screening + Phone Interview
The focus was mainly on my motivation and understanding of AI. They asked about my technical background and the most challenging project I had worked on. I was also asked why I wanted to join XAI, which is a fairly standard question. Finally, they asked if I had any questions for them.
Online Assessment (OA)
The interview platform was CodeSignal, with proctoring, video and microphone on throughout. Here are the real questions I encountered:
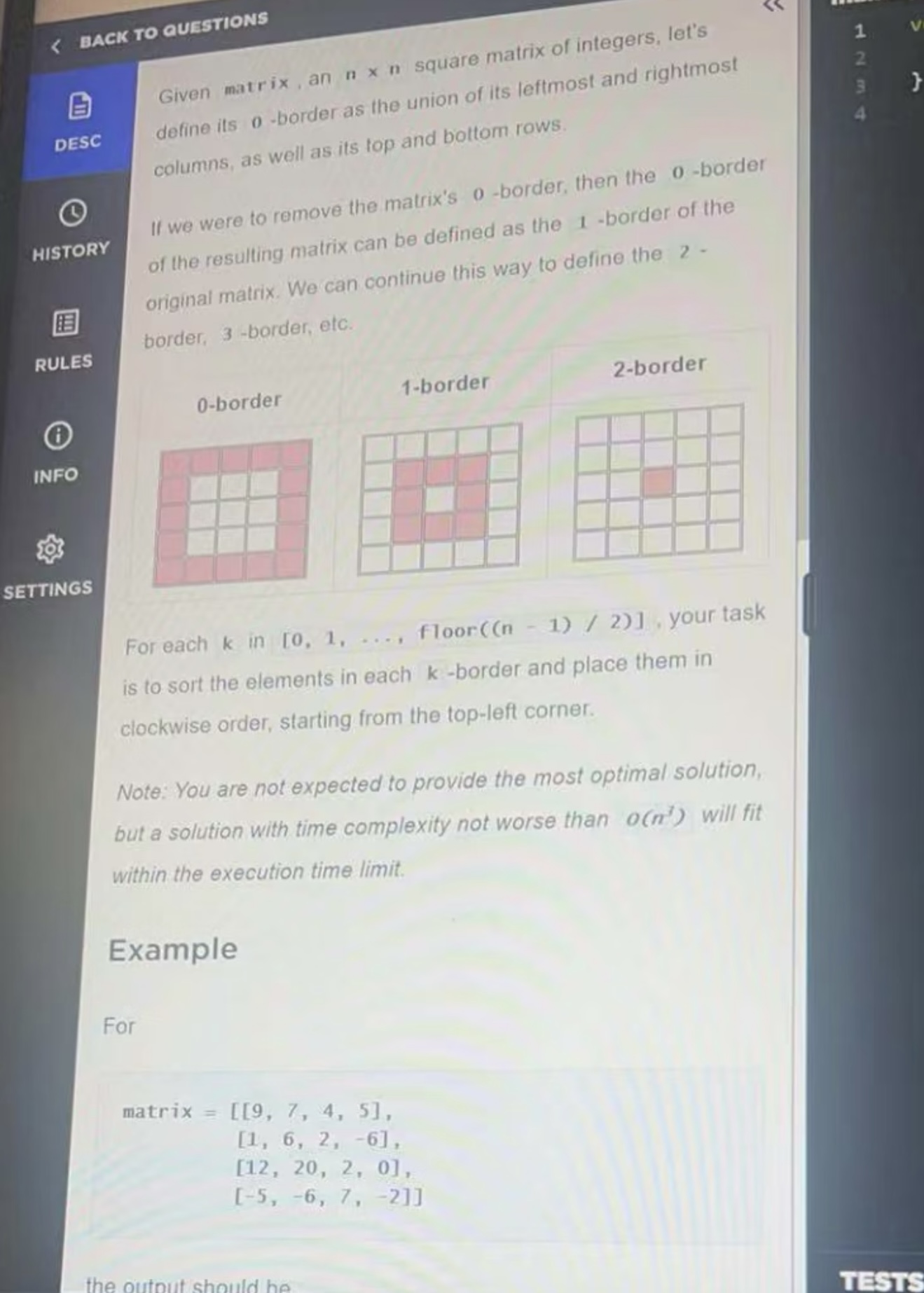
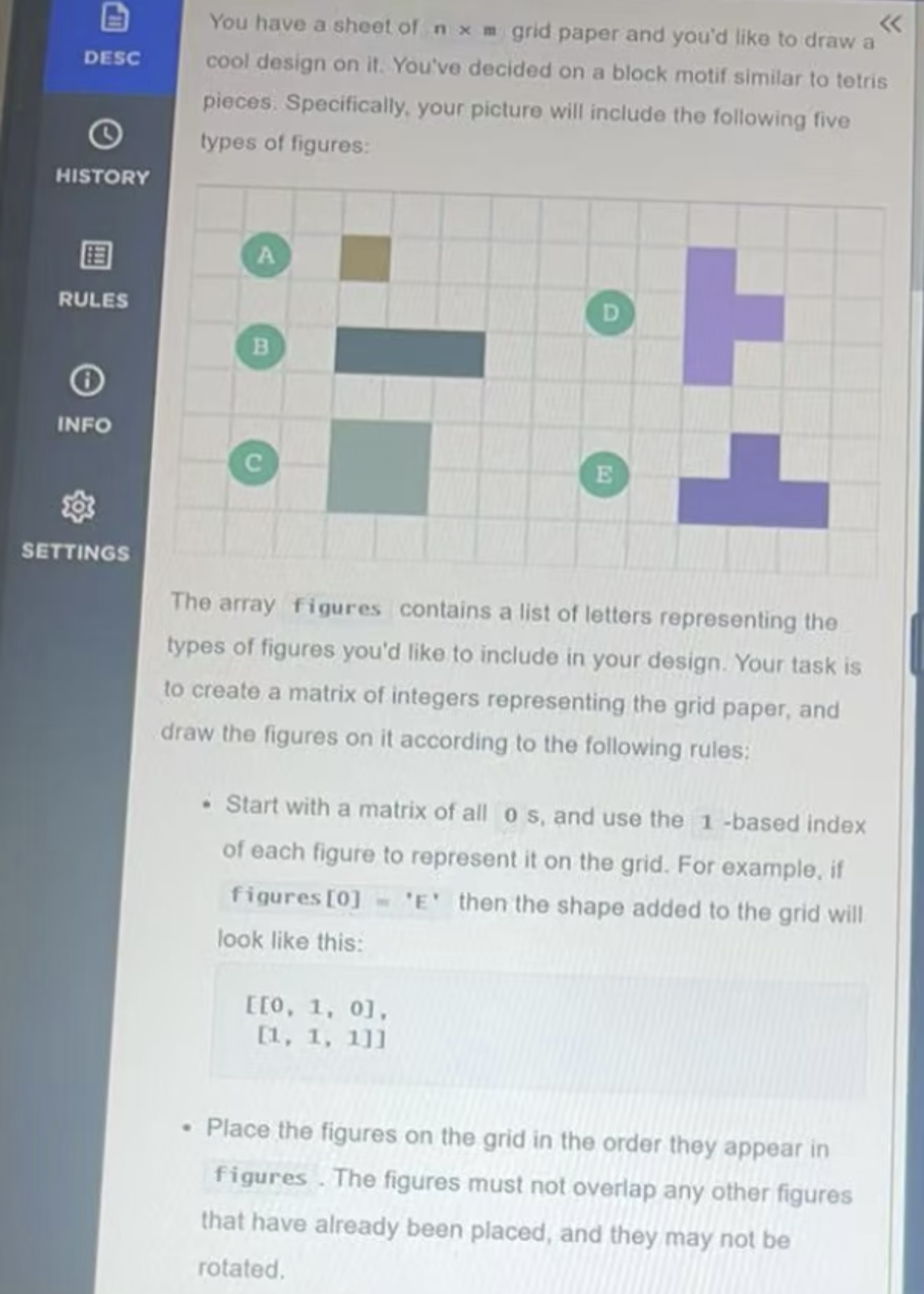
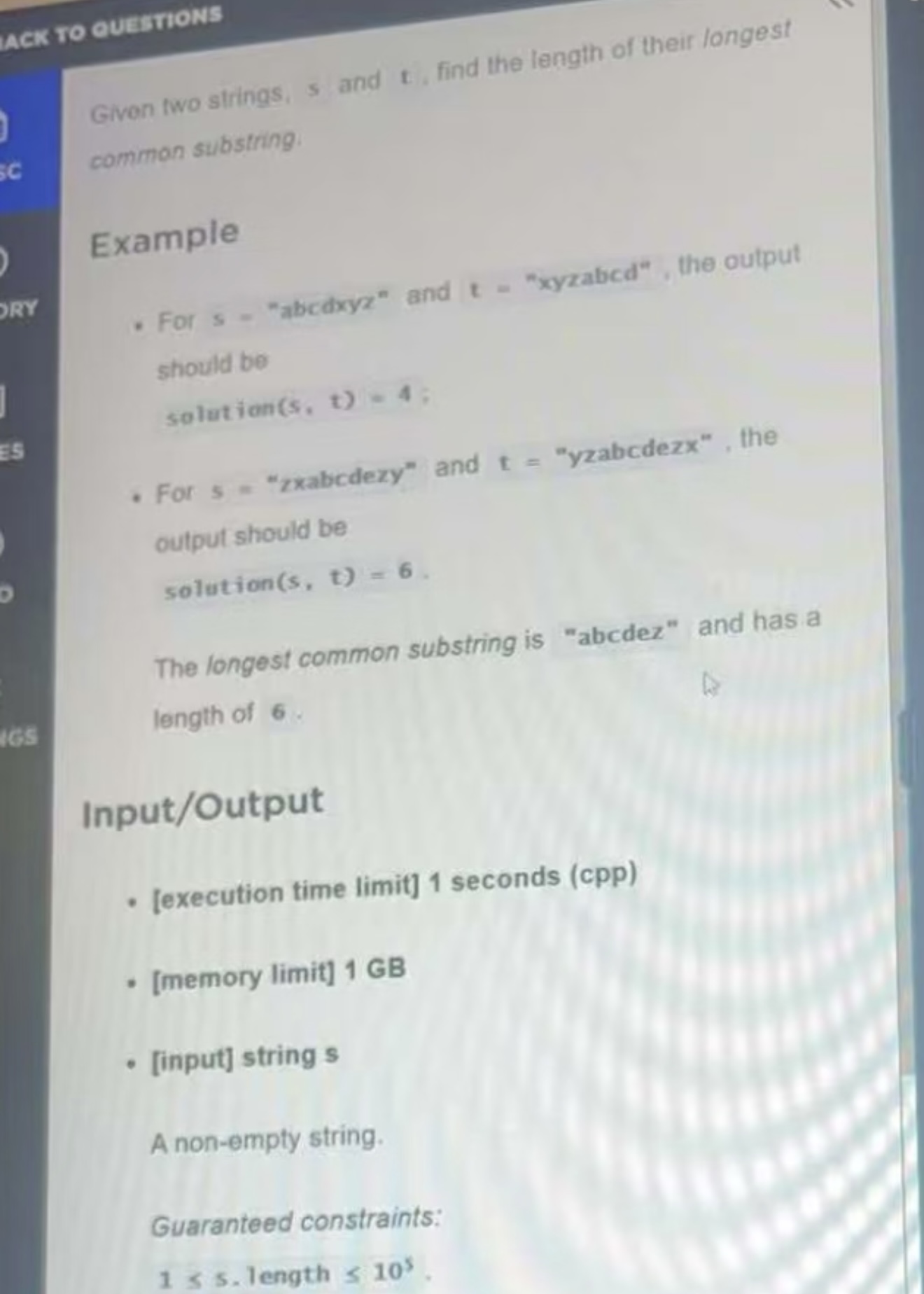
The OA only gave 60 minutes in total, so the timing was super tight. I used Linkjob to get through it. The AI worked great and I got through my interview without a hitch. It’s also undetectable, I used it and didn't trigger any HackerRank detection.
Technical Deep Dive
In this stage, the interview mainly focused on my understanding of Explainable AI (XAI) and model interpretability. The interviewer asked me to describe in detail how I would design an interpretability framework for a real-world deep learning model. They wanted to see not only my theoretical knowledge but also whether I could apply these concepts in practice.
Virtual Onsite
Round 1: Coding with Concurrency
The first round was quite unusual. They asked me to implement a piece of production-level code on the spot and to incorporate concurrency. It wasn’t a simple algorithmic exercise. Writing production-ready concurrent code live definitely took some effort and felt more like real-world engineering than a standard interview puzzle.
Round 2: Research Discussion + ML Fundamentals
The second round was more of a research-oriented discussion, heavily based on my resume. The interviewer dug into my past projects, and along the way slipped in a few ML fundamentals. These were on the easier side, things like the basics of neural network training, so as long as you’re comfortable with standard ML concepts, you should be fine.
Round 3: LeetCode-style Coding
The third session was a coding interview inspired by a real production problem. It felt like a medium-level LeetCode question. After solving it, the interviewer followed up with questions on testing strategies and handling corner cases, which made it more thorough than just a standard coding round.
Round 4: Behavioral Questions + Culture Fit
This round was slightly more conventional, and I’ll explain the specific interview questions in detail below.

XAI Interview Questions
The following content includes the questions I personally encountered during the interview, as well as the interview insights I compiled while preparing. I’ve organized them by question type, and it also includes strategies and tips for how to approach and answer them.
XAI Technical Fundamentals Interview Questions
Question 1: Explain the core components of the Transformer architecture and analyze why it is more suitable for large language models than RNN.
Examination Focus: The fundamental understanding of modern NLP architecture.
Answering Strategy:
Start with the multi-head attention mechanism. Explain that attention enables the model to focus on different parts of the input simultaneously, unlike RNN’s sequential processing. Its O(n²) complexity can be fully parallelized, which is crucial for large models.
Introduce position encoding to provide sequence information. Mention absolute vs relative positional encoding and why relative encoding performs better on longer sequences.
Briefly note that feed-forward networks provide non-linearity, and layer normalization with residual connections stabilizes training, especially in deep networks.
Question 2: How to design a distributed training system for training a language model with over 100B parameters?
Examination Focus: Large-scale ML engineering capabilities.
Answering Strategy:
Discuss trade-offs between data parallelism and model parallelism. For models over 100B parameters, pure data parallelism is insufficient, so model or pipeline parallelism is needed.
Explain tensor parallelism (splitting layers across GPUs) and pipeline parallelism (placing layers in stages), noting the need to manage scheduling to avoid idle time.
Mention memory optimization techniques like gradient accumulation, mixed precision training, gradient checkpointing, and ZeRO optimizer state sharding.
Point out the importance of communication efficiency, especially bandwidth requirements for all-reduce operations.
Question 3: Explain the different variants of gradient descent and analyze their applicability in large - scale training.
Examination Focus: The understanding of optimization algorithms in large-scale training.
Answering Strategy:
Start with basic SGD, highlighting momentum to reduce oscillations and speed up convergence.
Explain Adam’s combination of momentum and adaptive learning rates, noting memory overhead for large models, and mention AdamW’s decoupled weight decay.
Discuss learning rate scheduling, emphasizing the warmup phase for large models.
For large-scale training, consider optimizer memory footprint. Adam stores first and second moment estimates, which is significant for billion-parameter models. Newer optimizers like Lion or Sophia reduce this overhead.
XAI System Design Interview Questions
Question 4: Design a real - time inference system to serve the Grok model, which needs to support 100,000 requests per second.
Examination Focus: System design skills and understanding of production ML systems.
Answering Strategy:
Consider the model serving architecture, including load balancing, caching, and auto-scaling strategies.
Highlight model quantization as a key optimization. INT8 or INT4 quantization can reduce memory footprint and inference latency. Discuss trade-offs between dynamic and static quantization.
Question 5: How to design a data pipeline to process and clean massive text datasets used for training Grok?
Examination Focus: The ability to handle large - scale data processing and cleaning.
Answering Strategy:
Data quality is crucial for language model performance. Design a scalable data ingestion system for petabyte-scale datasets from multiple sources.
Deduplication is essential, using efficient algorithms such as MinHash or SimHash for near-duplicate detection.
Content filtering should include language detection, quality scoring, toxicity filtering, and removal of privacy-sensitive information. Track data quality metrics and ensure reproducibility.
Question 6: Explain how to implement an efficient attention mechanism for very long sequences (e.g., 100K tokens).
Examination Focus: The ability to optimize the attention mechanism for long sequences.
Answering Strategy:
Standard attention has quadratic complexity, which is prohibitive for long sequences.
Use efficient attention mechanisms. Sparse patterns such as local attention, strided attention, or random attention can reduce complexity to O(n√n) or O(n log n).
XAI Algorithm Optimization Interview Questions
Question 7: How to optimize CUDA kernels to accelerate the training and inference of the Transformer model?
Examination Focus: Low - level optimization skills.
Answering Strategy:
Understand the GPU memory hierarchy, including global memory, shared memory, and registers, and their access patterns.
Memory coalescing is crucial for performance. Use shared memory to reduce global memory accesses, especially for matrix multiplications.
Balance threads per block, registers per thread, and shared memory usage for occupancy optimization. Kernel fusion can reduce memory bandwidth by combining multiple operations.
Question 8: Design a memory - efficient training algorithm for billion - parameter models on limited GPU memory.
Examination Focus: The ability to design training algorithms under memory constraints.
Answering Strategy:
Memory is the main constraint for large model training.
Gradient checkpointing trades computation for memory by recomputing activations during the backward pass.
Question 9: How to implement efficient beam search for text generation and optimize its memory usage?
Examination Focus: The understanding of text generation decoding strategies and memory optimization.
Answering Strategy:
Beam search maintains multiple candidate sequences and can consume significant memory.
Batch beam search improves GPU utilization but requires careful handling of variable-length sequences.
Memory optimization techniques include dynamic vocabulary pruning, early stopping, and length normalization. Alternative decoding strategies like nucleus sampling or top-k sampling offer trade-offs in quality and efficiency.
XAI Advanced Deep Learning Interview Questions
Question 10: Explain different types of attention mechanisms and analyze their effectiveness in language modeling.
Examination Focus: The understanding of various attention mechanisms.
Answering Strategy:
Multi-head attention allows the model to attend to different representation subspaces simultaneously.
Each head can focus on different types of relationships, such as syntactic, semantic, or positional.
Question 11: How to design and implement custom loss functions for language model pre - training?
Examination Focus: The ability to design loss functions for specific pre - training tasks.
Answering Strategy:
Standard language modeling loss is cross-entropy, but label smoothing can reduce overconfidence.
Auxiliary losses can improve stability and model quality, such as regularizing attention weights or hidden states.
Curriculum learning can gradually increase task difficulty, and multi-task learning with shared representations can improve generalization while balancing losses.
Question 12: Explain different strategies of model parallelism and analyze their communication overhead.
Examination Focus: The understanding of model parallelism and its communication characteristics.
Answering Strategy:
Data parallelism replicates the model across devices, with communication mainly from gradient synchronization using all-reduce operations.
Pipeline parallelism distributes layers into stages, requiring careful scheduling to minimize idle time, with communication occurring between adjacent stages.
XAI Practical Application Interview Questions
Question 13: How to design an A/B testing framework to evaluate the improvements of a language model?
Examination Focus: The ability to design evaluation frameworks for language models.
Answering Strategy:
Evaluating language models is harder than traditional ML because outputs are open-ended. Combine automatic metrics with human evaluation.
Automatic metrics include perplexity, BLEU, ROUGE, and model-based metrics like BERTScore.
Human evaluation requires careful criteria and measures for consistency and bias. Account for statistical significance with proper sample sizes and power analysis.
Question 14: How to monitor and debug the performance degradation of a production language model?
Examination Focus: The ability to ensure the stable operation of production models.
Answering Strategy:
Performance may degrade due to data drift, infrastructure changes, or adversarial inputs. A comprehensive monitoring system is needed.
Monitor latency, throughput, error rates, and quality metrics, and set alerting thresholds with escalation procedures.
Question 15: Design a system to handle toxic content detection and filtering in real - time.
Examination Focus: The ability to design real - time content detection systems.
Answering Strategy:
Toxicity detection requires multiple layers. Rule-based filters catch obvious cases, while ML models handle subtle toxicity.
Model ensembles can improve accuracy and reduce false positives. Real-time constraints require efficient inference and caching.
Human-in-the-loop is needed for edge cases, with review workflows and feedback mechanisms for continuous improvement.
XAI Other Interview Question Collection
Mixture - of - Experts Architecture and Optimization
Question 1: MoE Architecture Design
Question 2: MoE Training Optimization
Question 3: Dynamic Expert Scaling
Large - Scale Distributed Training
Question 4: Colossus Supercomputer Optimization
Question 5: Memory - Efficient Training
Question 6: Training Data Pipeline
Multimodal Capabilities and Reasoning
Question 7: Multimodal Architecture Integration
Question 8: Reasoning Model Optimization
Question 9: Context Window Scaling
Code Generation and Professional Applications
Question 10: Grok Code Specialization
Question 11: IDE Integration System
Open - Source Strategy and Model Deployment
Question 12: Open Source Model Release
Question 13: Model Serving Infrastructure
Evaluation and Security
Question 14: Benchmark Design for Reasoning
Question 15: Safety and Alignment
Future Development and Integration
Question 16: Grok - Robot Integration
Question 17: Machine Interface Integration
Question 18: Scaling to Superintelligence
Core Examination Directions of XAI Interview
Large - scale distributed training technology, such as parallel strategies and optimization techniques related to the training of language models with over 100B parameters.
In - depth understanding of the Transformer architecture, including the role and advantages of each component and its adaptation in large models.
System design capabilities, covering the design of real - time inference systems, data pipelines, and toxic content detection systems.
Knowledge of algorithm optimization and advanced deep learning, as well as the ability to evaluate, monitor, and debug models in actual production environments.
XAI Interview Preparation Strategies and Tips
Deep Learning Fundamentals: Not just knowing how to use frameworks, but understanding the underlying mathematics and algorithms.
System Design Skills: Able to design large-scale distributed ML systems.
Coding Ability: Beyond LeetCode—capable of implementing complex ML algorithms from scratch.
AI Safety Knowledge: Familiar with current research in AI alignment, bias mitigation, interpretability, and related areas.
Research Experience: Ideally with top-tier conference publications or significant open-source contributions.
Business Understanding: Understanding the challenges and opportunities of AI in real-world applications.
FAQ
Do I need prior experience with Explainable AI (XAI) projects to succeed in the interview?
Not strictly. While having hands-on XAI experience helps, the interview also values your ability to reason about model interpretability, ethical AI, and bias mitigation concepts. Demonstrating strong theoretical understanding and problem-solving skills can often compensate for a lack of direct project experience.
How technical are the XAI interview questions compared to standard ML interviews?
XAI interviews tend to emphasize conceptual clarity over raw coding speed. Expect questions on SHAP, LIME, and interpretability trade-offs, sometimes framed in real-world scenarios. It’s less about solving a LeetCode-style puzzle and more about explaining your reasoning and evaluating model behavior.
Are there any common pitfalls candidates face in XAI interviews?
Yes. One is overcomplicating explanations. Interviewers prefer clear, concise reasoning. Another is ignoring ethical considerations when discussing model decisions. Finally, candidates often focus too narrowly on one tool (like SHAP) instead of demonstrating a broader understanding of interpretability techniques and their limitations.
See Also
My genuine xAI CodeSignal assessment interview experience in 2025
How to Use Technology to Cheat in CodeSignal Proctored Exams

© Copyright 2025 Linkjob.ai - All Rights Reserved.