My 2026 Bloomberg New Grad Interview: Process and Questions


Bloomberg's 2026 New Grad interview has several stages: resume screen, technical screen, and virtual onsite, with a total of 6 interview rounds. I found it quite difficult because the time given for coding was very tight. Moreover, the technical interviews used Zoom and required the camera to be on, and the interviewer also asked me to share my screen.
I’m really grateful to Linkjob.ai for helping me pass my interview, which is why I’m sharing my interview questions and experience here. Having an undetectable AI interview assistant for online interview indeed provides a significant edge.
Bloomberg New Grad Interview Timeline
I applied about a week after getting a referral, and another week later I received a phone screen invitation. About two weeks after that, I had the technical phone screen, which lasted around 45 minutes. Three days later, I got the VO (virtual onsite) invitation. Since the on-campus slots were full, I scheduled mine for the following week.
The VO was structured as back-to-back interviews, with three rounds in total, all conducted over Zoom. The morning round wasn’t very difficult, and at the end I asked what the next steps were. They told me to just rejoin the same Zoom link. In the afternoon round, I worked a bit slowly on the coding problems, but the interviewer didn’t rush me. After that, about 30 minutes later, I had my HR interview.
The HR questions included:
Why Bloomberg?
Most interesting project?
What new thing did you learn about Bloomberg from your previous interviews?
Two things you are looking for when you apply to jobs?
They also asked some basic questions, like: When are you graduating? Do you need sponsorship? Do you have any other offers? About a week later, they informed me that I would be moving on to the next EM round.
Note: My impression is that when interviewing with Bloomberg, it’s important to communicate with the interviewer. Don’t be afraid to ask questions. I personally think they pay close attention to problem-solving habits and communication skills. Also, make sure you save the Zoom link! The entire superday used the same link.
Bloomberg New Grad Interview Interview Process and Questions
Resume Screening
The screening mainly focused on educational background, tech stack fit (primarily C++/Python/Java), and project experience.
Technical Screening
This round assessed fundamental algorithms and data structures, lasting about 45 minutes.
In my technical interview, I was given two algorithm problems. The emphasis was on clarity of thought, code correctness, and especially handling edge cases. Recursion and divide-and-conquer were frequently tested.
Problem 1: Counting Ships in a Grid
Prompt: Given a Point struct and an implemented hasShips function (which takes two Points, bottom_left and top_right, and returns whether there’s at least one ship in that region), implement countShips to return the total number of ships in the area.
My approach: I applied a divide-and-conquer strategy.
If hasShips on the current region returns false, return 0.
If the region is reduced to a single point (bottom_left equals top_right), return 1 if hasShips is true, otherwise return 0.
Otherwise, split the region into four quadrants, recursively count ships in each, and sum the results.
Result: I stumbled a bit on handling the single-point case, but then realized I just needed to return based on the hasShips result when the coordinates matched. For complexity, I reasoned that the recurrence is T(n) = 4T(n/4) + O(1) (assuming hasShips is O(1)), leading to O(log n). The interviewer seemed satisfied with my analysis.
Problem 2: Word Segmentation
Prompt: Given a string without spaces and a word dictionary, return a properly spaced string. Example: input "bloombergisfun" with dictionary ["bloom", "bloomberg", "is", "fun"], output "bloomberg is fun".
My approach: I used backtracking with memoization.
Convert the dictionary into a HashSet for quick prefix lookups.
Use a memo to store results of previously processed substrings to avoid recomputation.
At each recursive step, check if the prefix exists in the dictionary. If so, recursively process the remaining string and concatenate results, adding spaces where needed.
Result: All test cases passed, and I cleared this round smoothly.
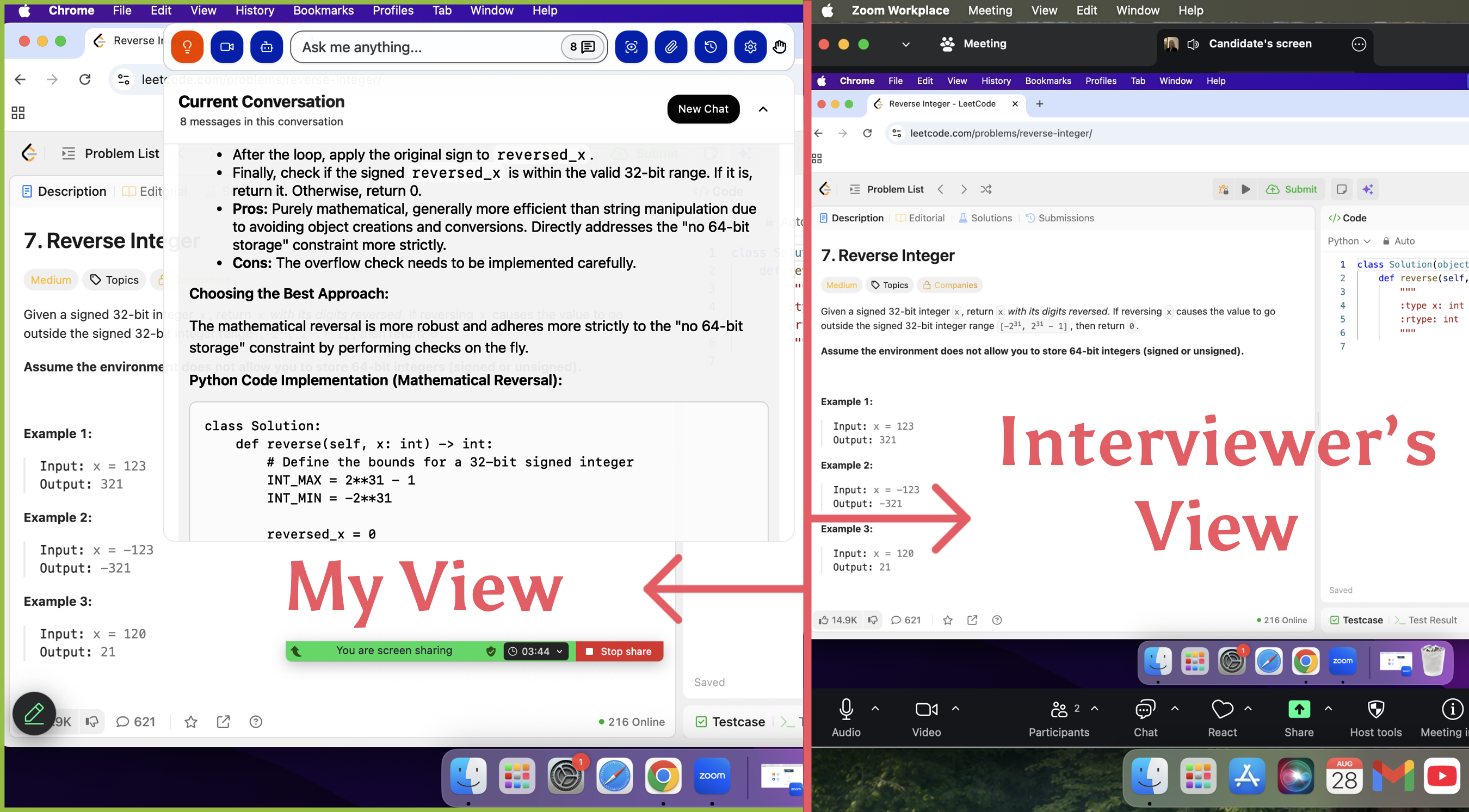
Linkjob AI worked great and I got through my interview without a hitch. It's undetectable, and the interviewer did not find that I used it.
Virtual Onsite
Round 1: LeetCode 445
Round 2, Problem 1: Process Hierarchy


Round 2, Problem 2: LeetCode 155 – Min Stack
The follow-up question was: How would the Min Stack track the minimum k elements?
Round 3, Problem 1
Given:
input_string = "bloombergissofun"
dictionary = ["bloom", "bloomberg", "is", "so","fun"]
You need to turn the input string into a sentence using the words in the dictionary.
output = "bloomberg is so fun"
Round 3, Problem 2
Given:
n kids and an integer k, starting from the first kid, kicking the kth kid out. Keep kicking until there is only one kid left.
example: n=6, k=4
round 1, you have 123456, start counting at kid 1, you should kick out kid 4
round 2, you have 12356, start counting at kid 5(next kid after 4), you should kick out kid 2(round robbin)
round 3, you have 1356, start counting at kid 3, you should kick out kid 1
round 4, you have 356, start counting at kid 3, you should kick out kid 3
round 5, you have 56, start counting at kid 5, you should kick out kid 6

Behavioral Questions
These are a few of the behavioral questions I encountered:
Please describe a complex technical problem you’ve solved and explain how you optimized the outcome.
How would you drive your team to reach consensus on a technical decision?
Why did you choose Bloomberg, and what is your understanding of fintech?
Additional Bloomberg New Grad Interview Questions
I also have some excellent real interview questions I came across while preparing, covering real-time data processing, low-latency trading systems, and financial data analytics platform design. I think all of these are highly relevant to Bloomberg’s business.
Problem 1: Real-time Market Data Processing
1. Problem Description
Design a system to process a stream of stock price updates (including stock_id, timestamp, price) and efficiently compute four types of statistics for any stock_id over a sliding window of the last N seconds:
Current price (latest price)
Average price (mean within the window)
Maximum price (highest within the window)
Minimum price (lowest within the window)
Additionally, handle out-of-order or duplicate updates and efficiently evict old data.
2. Solution
Data Structures:
stock_data (hash map): key = stock_id, value = StockWindowData object storing window data and statistics for a single stock.
StockWindowData (class/struct):
prices (deque): stores PriceEntry (timestamp + price) in ascending timestamp order
sum_prices (numeric): sum of prices in the window for fast average calculation
min_heap / max_heap: store PriceEntry for quickly getting min/max prices
expired_entries (hash map): marks outdated heap elements for lazy deletion
Core Algorithm:
process_update:
Look up or create StockWindowData by stock_id.
Remove expired entries from deque (timestamp < current - N*1000), update sum_prices and expired_entries, and remove expired elements from heaps.
Add the new PriceEntry to the deque, update sum_prices, and insert into min/max heaps.
query_statistics:
Get StockWindowData by stock_id.
Current price: last element in deque
Average price: sum_prices / prices.size()
Max/Min price: top of max/min heap (check expired_entries for validity)
Special Cases:
Out-of-order updates: keep deque sorted; small disorder can be discarded or buffered; complex cases require insertion at correct position.
Duplicate updates: if (stock_id, timestamp) is duplicated, either overwrite or ignore; default treats as separate points.
Complexity Analysis:
process_update: O(log K) time (heap operations dominate), O(K) space
query_statistics: O(1) time and space
Optimizations:
Lazy deletion via expired_entries to avoid frequent heap rebalancing
Circular queue to replace deque if window size predictable
Pre-aggregation by time buckets for large windows or high data volume
Problem 2: Low-Latency Trading System
1. Problem Description
Design a system to process order streams (Order with order_id, stock_id, type (BUY/SELL), price, quantity) to match buy and sell orders quickly, with a focus on low latency.
2. Solution
Data Structures:
buy_orders (max heap): highest-price buy orders at the top
sell_orders (min heap): lowest-price sell orders at the top
order_map (hash map): key = order_id, value = Order for fast lookup, update, or deletion
Core Algorithm (process_order):
Insert new order into order_map.
Matching logic:
BUY: check sell_orders top; if sell price ≤ buy price, match min quantity, create trade, update quantities; remove fully matched orders from heap and map; remaining buy quantity goes into buy_orders.
SELL: symmetrical logic with buy_orders.
Optimizations:
Sharding by stock_id to maintain separate order books
Memory optimization with object pools / compact data structures
Lock-free structures for multithreading (CAS operations)
Batch processing to reduce context switches
Hardware acceleration with FPGA/GPU for extreme low-latency
Pre-allocated memory pools to avoid dynamic allocation delays
CPU affinity for order-processing threads
Complexity Analysis:
process_order: amortized O(log K) per order (heap operations), each order inserted/deleted once
Problem 3: Financial Data Analytics Platform
1. Problem Description
Build a platform that allows users to query historical stock prices and calculate financial indicators (e.g., moving average MA, exponential moving average EMA, relative strength index RSI) over millions of data points, with efficient storage, indexing, and query.
2. Solution
High-Level Architecture:
Data Ingestion Layer: ingest batch/real-time data from exchanges or providers; store in data lake (HDFS/S3) or warehouse (Snowflake); metadata (stock info, sector) in relational DB (PostgreSQL/MySQL)
Processing & Computation Layer:
Real-time engine (Flink/Spark Streaming) for live metrics
Batch engine (Spark/Flink batch mode) for historical/complex metrics
Metric computation service: pull data from storage and calculate indicators
API Layer: RESTful/GraphQL APIs with authentication, authorization, and rate limiting
Frontend Layer: React/Angular/Vue dashboard for charts and analytics
Data Storage & Indexing:
Time-series DB (TSDB) optimization:
Composite key (stock_id, timestamp) for uniqueness and efficient lookup
Partitioning by time or stock_id for lifecycle management
Secondary index on stock_id
Columnar storage to read only required columns
Core Indicator Calculation (EMA example):
EMA_today = Price_today * K + EMA_yesterday * (1-K), K=2/(N+1), N=period
Initialize with SMA, then iterate
Query Performance Optimization:
Caching: Redis/Memcached for common results; Apache Ignite for hot raw data
Pre-computation: compute high-frequency metrics (50-day MA) after market close
Distributed processing: Spark/Flink for large-scale queries
Index optimization: covering indexes to avoid table scans
Data compression: reduce disk I/O and network transfer
Bloomberg Interview Preparation Tips
Algorithm Practice: Focus on high-frequency LeetCode problems (Top 100) and original LintCode problems (e.g., Longest Palindromic Substring, Maximal Square).
System Design Exposure: Read Designing Data-Intensive Applications and practice design cases (e.g., URL shortener service, distributed cache).
Behavioral Interview Simulation: Use the STAR method (Situation–Task–Action–Result) to structure your answers.
Tech Stack Preparation: Be familiar with C++ memory management and multithreading, or Java concurrency utilities.
Interview Insights: Bloomberg SDE interviews emphasize recursion and divide-and-conquer algorithms. During preparation, practice these types of problems extensively, while paying attention to code details and logical completeness.
FAQ
What is the best way to practice coding for Bloomberg interviews?
Use LeetCode, HackerRank, and CodeSignal.
Time yourself on each problem.
Review your mistakes and learn from them.
Practice explaining your solutions.
How do you show cultural fit during the interview?
Share examples of working with teams. Talk about learning new skills. Ask questions about Bloomberg’s values. Show that you care about growth and helping others.
Can I ask questions during the interview?
Yes! Prepare questions about the team, projects, and company culture. Asking questions shows you care and want to learn more. Write your questions down before the interview.
See Also
Here Is How I Cracked the Citadel SWE New Grad Interview in 2025
How I Passed My Palantir New Grad SWE Interview in 2025
My Experience of the Databricks New Grad Interview Process in 2025

© Copyright 2025 Linkjob.ai - All Rights Reserved.