How I aced the Databricks CodeSignal assessment in 2026


I received the Databricks CodeSignal invitation with a 7-day deadline. It is a 70-minute, proctored assessment (webcam and screen recording) consisting of 3–4 coding problems, serving as the primary filter for SWE intern and new grad roles.
I’m really grateful to Linkjob.ai for helping me pass my interview, which is why I’m sharing my OA questions and experience here. Having an undetectable AI coding interview assistant for my OA indeed provides a significant edge.
I ended up passing the OA and moving on in the process, so in this post I’ll walk through:
What my Databricks CodeSignal looked like
How the proctored setup felt in practice
The four real questions I got (descriptions + solution ideas)
How I managed time and prepped without burning out
My Databricks CodeSignal OA Experience
For context, this was for a Software Engineer Intern role in 2025. The flow for me (and in most public reports) looked like:
Apply online or via referral
Get an invite to a proctored CodeSignal assessment
If you pass, then recruiter chat → 1–2 technical rounds → behavioral / hiring-manager round
The CodeSignal part itself:
Duration: 70 minutes
Questions: 4 coding problems (for me: 2 easy, 1 medium, 1 medium-hard)
Environment: Fully proctored – webcam on, screen shared the whole time
Languages: Any of CodeSignal’s supported languages (I used Java)
Attempts: CodeSignal has global limits (e.g., limited attempts per 30 days / 6 months), so you don’t want to waste a run.
The timer only started once I’d completed camera + screen-share setup, which gave me a moment to breathe. After that, though, it was pure sprint: roughly 15–18 minutes per question if you want time to review at the end.

Linkjob AI worked great and I got through my interview without a hitch. It’s also undetectable, I used it and didn't trigger any CodeSignal detection. Here's how I cheated on the CodeSignal proctored test.
Databricks CodeSignal OA Format and Process Overview
Real Databricks CodeSignal Coding Questions
Below are the exact types of problems I saw (rebased into my own words), plus how I solved them and what I’d do differently if I had to retake it.
Question 1 – Even vs Odd Index Sum (Warm-up)Question Types
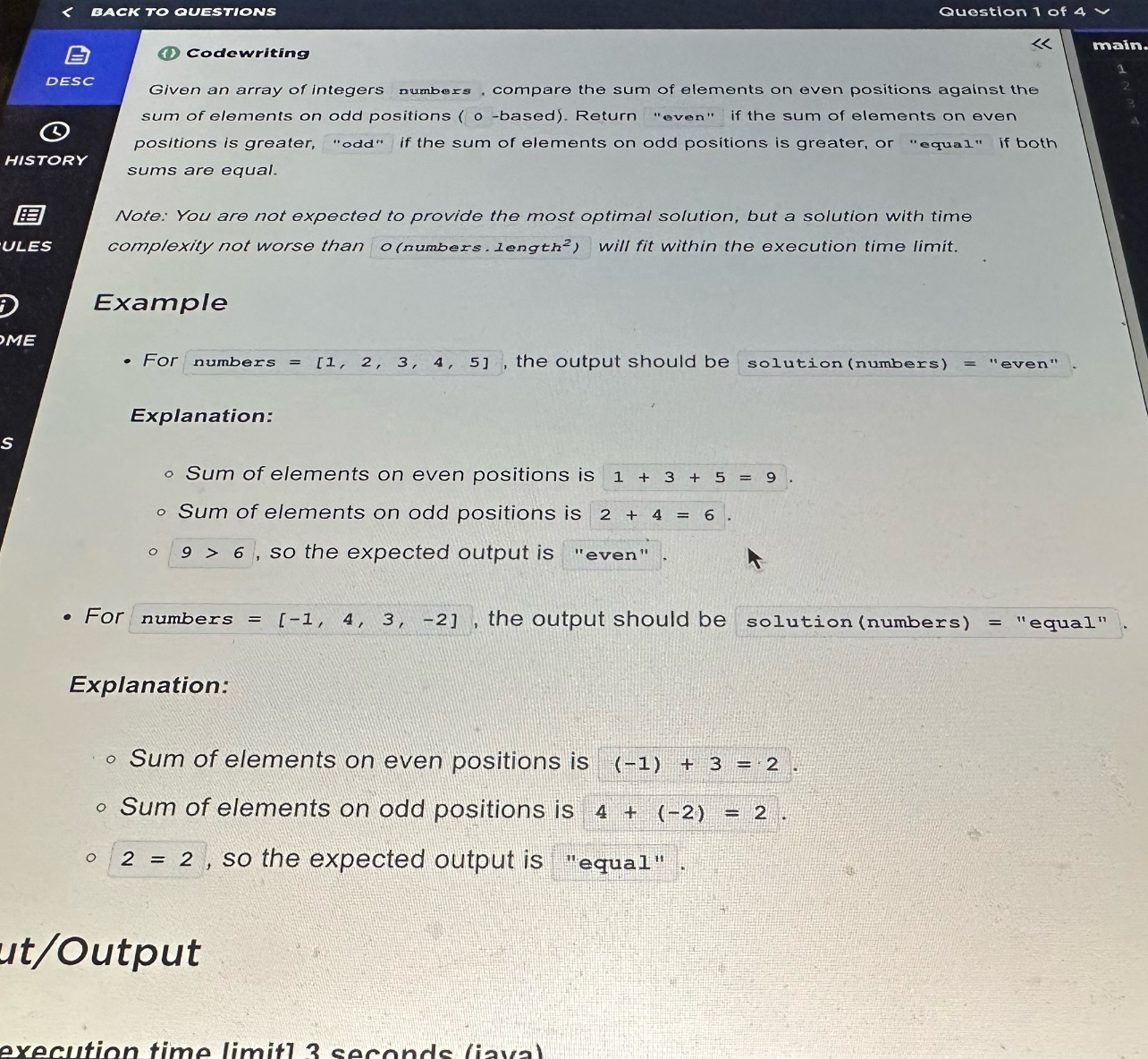
Type: Arrays, prefix sums
Difficulty: Easy
You’re given an integer array numbers. Using 0-based indexing, compare:
evenSum= sum of elements at indices 0, 2, 4, …oddSum= sum of elements at indices 1, 3, 5, …
Return:
"even"ifevenSum > oddSum"odd"ifoddSum > evenSum"equal"otherwise
Example:
numbers = [1, 2, 3, 4, 5]→ even positions: 1 + 3 + 5 = 9, odd positions: 2 + 4 = 6 → return"even".numbers = [-1, 4, 3, -2]→ both sums = 2 →"equal".
My approach
This is a straight warm-up to get you moving:
Initialize
evenSum = 0,oddSum = 0.Loop over indices
ifrom 0 ton-1:If
i % 2 == 0, addnumbers[i]toevenSum; else tooddSum.
Compare the two sums and return the correct string.
I wrote this one carefully but quickly. My goal was to be done in under 5 minutes to leave room for later questions.
Time complexity:
O(n)Space:
O(1)
Tip: Treat Q1 as a confidence booster. Don’t overthink it, but also don’t introduce silly bugs. One WA here is painful because it’s basically free points.
Question 2 – Replaying Shell Commands (cp, ls, mv, !k)
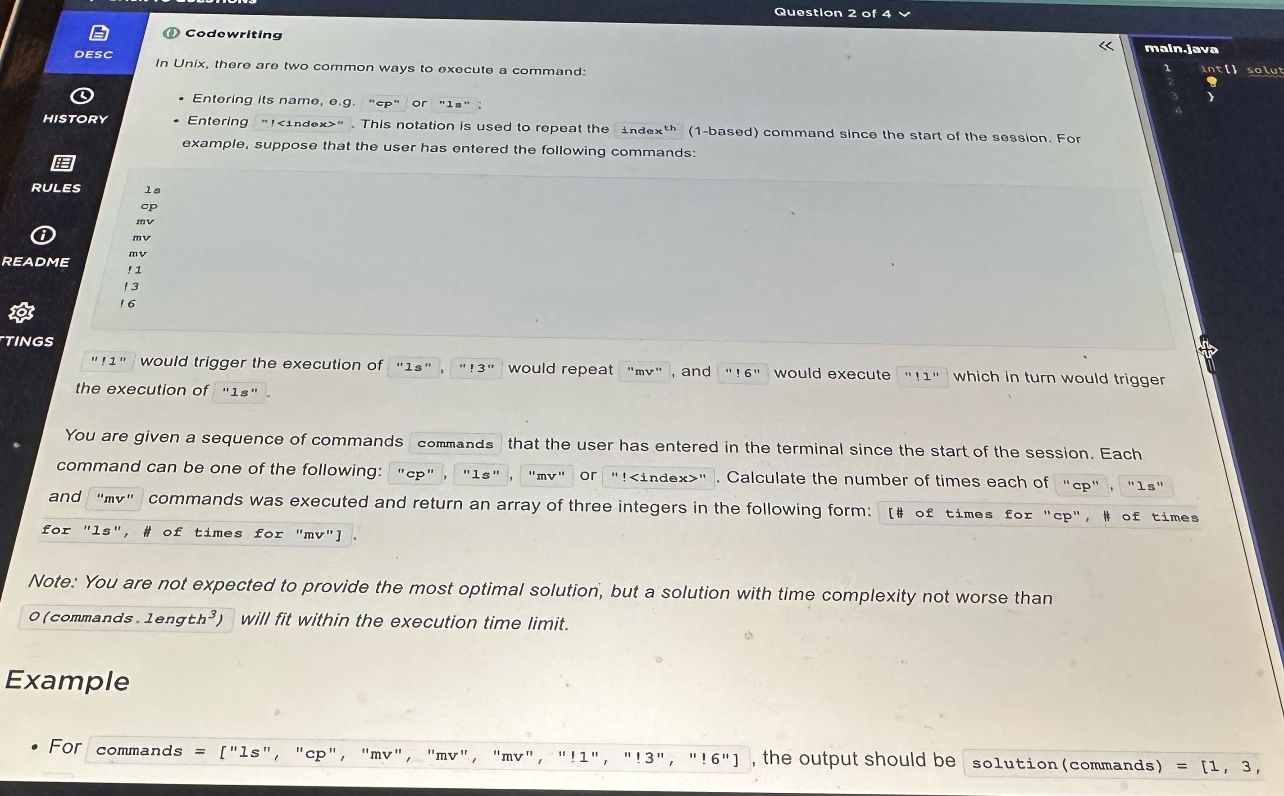

Type: Strings, simulation, recursion / DFS
Difficulty: Easy–Medium
The prompt models a Unix-like shell history.
You’re given a list of commands entered by the user in one session. Each command is one of:
"cp""ls""mv"or
"!<index>", where<index>is 1-based and refers to a previous command in the same list.
Examples of history:
ls
cp
mv
mv
mv
!1
!3
!6
Semantics:
Typing
"ls"executeslsonce.Typing
"!3"executes whatever command is at index 3 (here:"mv") as if the user typed"mv".If that referenced command is itself something like
"!1", you follow that again (so"!6"might trigger"!1", which then triggers"ls").
You must return an array [countCp, countLs, countMv] giving how many times each of the three real commands actually ran.
The statement says a solution with complexity up to about O(commands.length^3) is fine, so constraints are relaxed.
My approach
I treated each command as an instruction node and recursively “expanded” "!k" into the underlying real command.
Parse the input array
commands.Write a helper
execute(i)that simulates running command at indexionce:If
commands[i]is"cp", incrementcountCp.If
"ls", incrementcountLs.If
"mv", incrementcountMv.If it starts with
'!', parse the number after'!':k = int(commands[i].substring(1)) - 1(convert to 0-based index).Call
execute(k).
Then in the main loop, for each index
ifrom 0 ton-1, just callexecute(i)once.
Because each "!k" always refers to an earlier command (1-based index since start of session), there is no cycle; recursion depth is at most n. That’s why this simple DFS is safe.
Time complexity: worst-case
O(n^2)if every command is an indirection chain into previous ones.Space:
O(n)recursion stack in the worst case.
I spent a bit of time making sure I didn’t off-by-one the index or mis-parse the ! prefix. I also added a couple of internal prints while debugging, then removed them before final submission.
Prep tip: Practice 2–3 “simulation” problems where you replay a log of instructions or history. The main danger is just getting indices wrong under time pressure.
Question 3 – Splitting an SMS into <x/y> Messages
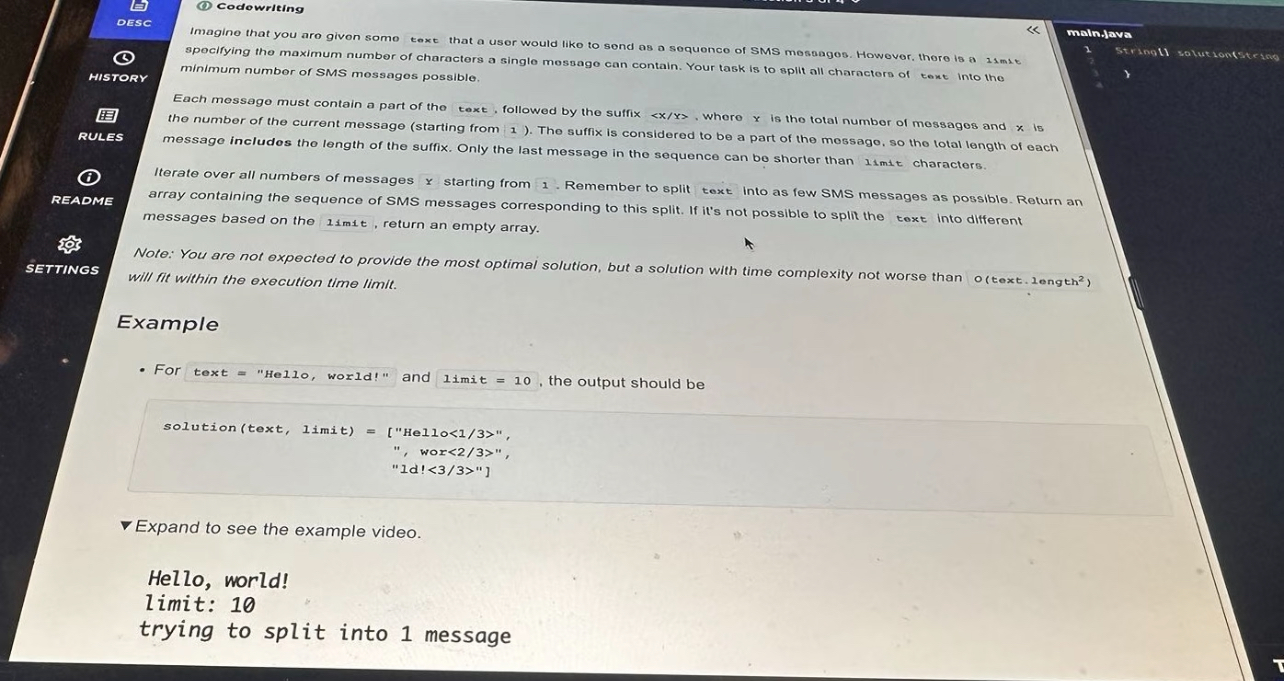
Type: Strings, greedy, implementation
Difficulty: Medium–Hard (because of edge cases)
Imagine you have a long string text that a user wants to send as a sequence of SMS messages. Each message:
contains a contiguous part of
text(no reordering),plus a suffix
"<x/y>"whereyis the total number of messages,xis the current message index (1-based).
There’s also a global limit: maximum total characters per message, including the suffix.
We must:
Split
textinto as few messages as possible,Under these rules:
Every message must be ≤
limitcharacters.Only the last message is allowed to be shorter than
limit; all previous messages must exactly fill thelimit(suffix included).
If no valid splitting exists for any
y, return an empty array.
Example (simplified from the prompt):
text = "Hello, world!"
limit = 10
Output: [
"Hello<1/3>",
" , wor<2/3>",
"ld!<3/3>"
]
Notice:
"<1/3>"length = 5 → first message can hold 5 characters of text (10 - 5).All non-final messages are exactly 10 chars long.
My approach
This problem is tricky because the suffix length depends on y, and we don’t know y at the start. So I did what the prompt hints at: try possible values of y starting from 1.
High-level algorithm:
For
yfrom 1 upwards:Build
ymessages greedily.If we can assign all characters of
textintoymessages under the rules, we return that split.If at some point no splitting is possible for a given
y, move toy + 1.Put a reasonable upper bound on
y(e.g.,len(text)).
For a fixed
y, simulate the split:pos = 0 # pointer into text messages = [] for x in 1..y: suffix = "<" + x + "/" + y + ">" cap = limit - len(suffix) # max text chars in this message if cap <= 0: impossible for this y if x < y: # all messages except last must be exactly full length if pos + cap > len(text): impossible for this y chunk = text[pos : pos + cap] pos += cap else: # last message takes all remaining chars chunk = text[pos :] if len(chunk) > cap: impossible for this y pos = len(text) messages.append(chunk + suffix) After the loop, if pos == len(text), we succeeded.If we reach a
ywherepos == len(text)and we’ve built exactlyymessages, that’s the minimaly(because we tested in increasing order), so we returnmessages.
Time complexity: For each candidate
ywe scan the string once → roughlyO(y * len(text)). In the worst-case,ycan be up tolen(text), hence aboutO(len(text)^2), which is exactly what the statement allows.Space:
O(len(text))for building the messages.
This one ate the most time for me because of corner cases:
Cases where
limitis so small that even<1/1>doesn’t fit.textso short thaty=1already works.Two-digit
xandychanging the suffix length (e.g.<10/10>vs<2/10>).
I highly recommend practising 1–2 “split string with suffix/prefix” style problems before your OA; once you see the pattern, this becomes mechanical.
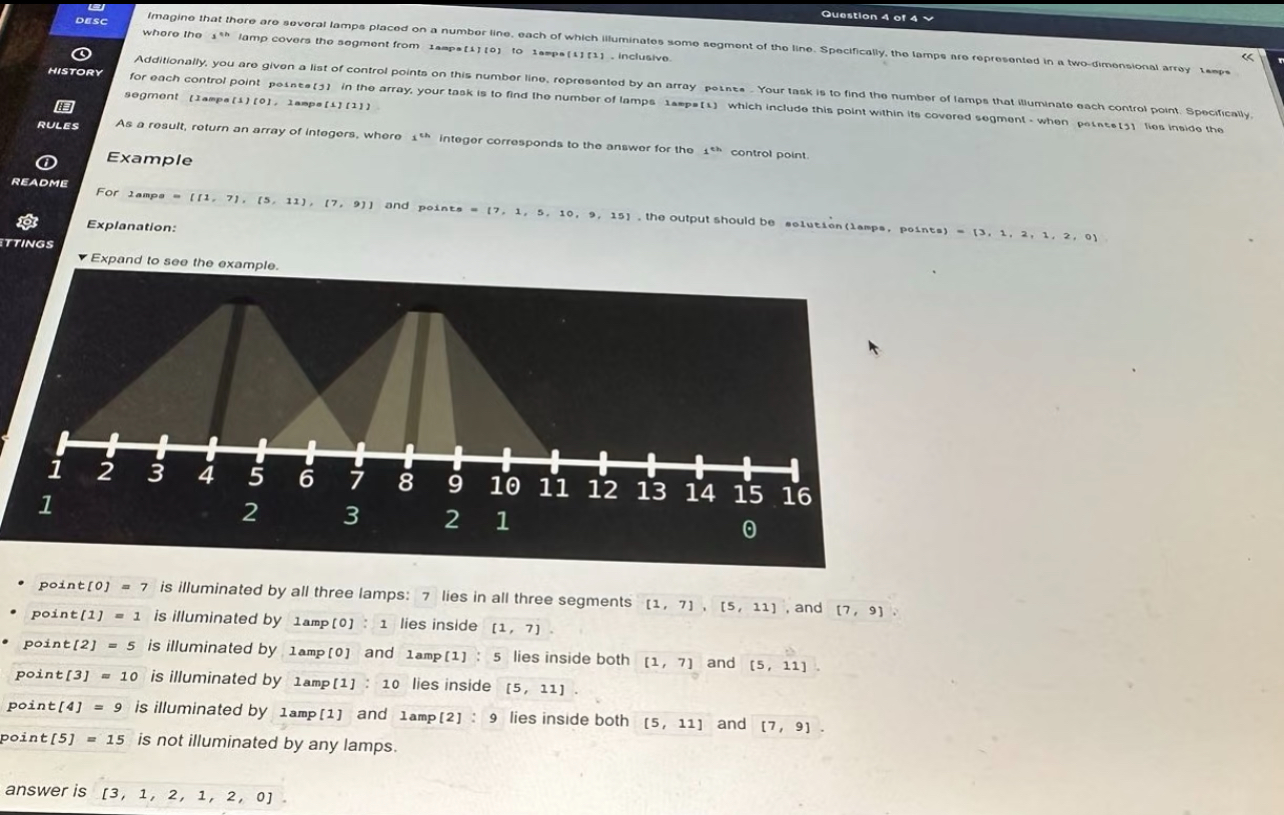
Question 4 – Lamps on a Number Line
Type: Arrays, intervals, sweep line / brute force
Difficulty: Easy–Medium
You’re given several lamps on a number line. Each lamp i illuminates an inclusive segment [L[i][0], L[i][1]].
You’re also given an array points of “control points” on the number line. For each point p, you must count how many lamp segments cover that point (i.e., for how many i does L[i][0] ≤ p ≤ L[i][1]).
Return an array result where result[j] is the count for points[j].
Example:
lamps = [[1, 7], [5, 11], [7, 9]]
points = [7, 1, 5, 10, 9, 15]
result = [3, 1, 2, 1, 2, 0]
Explanation:
7 is in all three segments → 3
1 is only in [1, 7] → 1
15 is in no segment → 0, etc.
The note in the problem explicitly said that a solution around O(lamps.length * points.length) is acceptable, so we don’t need anything super fancy.
My approach (simple & safe)
Because the constraints were forgiving, I went with a direct double loop:
Initialize
resultarray lengthm(number of points) with zeros.For each
jfrom 0 tom-1:For each lamp
[start, end]:If
start <= points[j] <= end, incrementresult[j].
Time complexity:
O(L * P)whereLis number of lamps andPnumber of points.Space:
O(P).
This is enough to pass with the given constraints and is extremely straightforward to implement under time pressure.
Faster idea (if constraints were huge)
If they had tighter constraints, a classic improvement would be:
Build a difference array using “events” at lamp starts and ends,
Sort both events and points,
Sweep from left to right keeping track of how many lamps are currently “on”.
But for the OA I didn’t bother; the instructions basically told me I didn’t need that level of optimization.
Scoring Insights
The scoring system felt unique. My final score looked like a credit score, ranging up to 850. I learned that getting a high score did not guarantee an interview. I saw stories where candidates scored 600 out of 600 but did not move forward. Others got 498 and missed the next round. Databricks looks at more than just your score. They care about how you solve data problems, write readable code, and handle tricky edge cases.
Assessment Type | Number of Questions | Time Limit | Scoring Method |
|---|---|---|---|
CodeSignal | 4 | 70 minutes | Resembles a credit score |
What matters most? I focused on correctness, time complexity, and making my solutions easy to read. I paid extra attention to edge cases, especially in sql queries. That approach helped me stand out.
Time Management and Stress Strategies in the Databricks CodeSignal OA
During my preparation, I learned from the experiences from other candidates at first, including Databricks system design interview and Databricks new grad interview process & questions. Here’s how I approached the actual 70 minutes.
1. Question order & time budget
My plan going in:
Q1 (warm-up): ≤ 5 minutes
Q2 (simulation): 10–15 minutes
Q3 (string/SMS): 25–30 minutes (hardest one)
Q4 (intervals): Whatever time remained
I quickly skimmed all four questions in the first ~2 minutes and mentally tagged difficulty. Then I followed this order:
Do all obvious / short problems first (Q1 & Q4 in my case).
Tackle simulation (Q2) next – easy conceptually, but I wanted some buffer for debugging recursion.
Dedicate the largest contiguous chunk to the string-splitting beast (Q3).
I kept an eye on the clock every ~5–7 minutes so I wouldn’t sink 40 minutes into one question.
2. Debugging strategy inside CodeSignal
Because you don’t have an IDE with full debugging tools, I did:
Use small, custom test cases early.
Add quick
printstatements (and then remove them) to verify:For Q2: what
execute(i)actually calls when it hits"!k".For Q3: lengths of
suffixand chunks at eachx/y.
When I fixed a bug, I re-ran all sample tests plus 1–2 edge cases I thought of.
CodeSignal lets you run your code multiple times, so use that freedom wisely.
3. What I Practiced Beforehand (and it helped)
Looking back, the best prep for this Databricks OA was:
Simulation problems: Replaying commands, processing logs, modeling simple machines.
String manipulation: Splitting, joining, handling variable-length suffix/prefix, careful indexing.
Arrays & intervals: Basic counting problems (prefix sums, sweep line ideas).
Speed drills: Set a 15–20 minute timer and try to fully solve one medium problem from scratch.
Public interview guides and candidate experiences mention that Databricks’ CodeSignal rounds typically cover arrays, hashing, matrices, strings, graphs, and sometimes DP, with 3–4 questions in ~70 minutes.
So I focused my practice exactly on those patterns rather than trying to grind every LeetCode category on earth.
Final Thoughts on the Databricks CodeSignal OA
The Databricks CodeSignal OA is stressful mostly because:
It’s proctored (camera + screen share),
You have very limited attempts overall on CodeSignal,
And 70 minutes for 4 questions doesn’t leave much room for paralysis.
But the upside is that the problems themselves are very solvable if you:
Nail the easy ones quickly and cleanly,
Handle simulation and string corner cases without panicking,
And practise writing bug-free code at speed.
Hopefully walking through my four real questions gives you a realistic picture of what you might face. If you prep with similar problems and simulate the time pressure a couple of times, the actual assessment feels a lot more like “just another practice set” and a lot less like a mystery boss fight.
FAQ
What should I do if I get stuck on a question?
I take a deep breath and move to the next problem. I come back later with fresh eyes. Sometimes, a quick sketch or writing out the logic helps me break through.
Can I use notes or search online during the assessment?
No, the test is closed-book. I rely on my memory and practice. I review key concepts before test day so I feel ready.
How should I use AI tools like Linkjob.ai?
You can simply use its screenshot analysis feature directly. The AI will provide the coding approach and a reference answer. The app is completely invisible/stealthy, so you can use it without worry.
See Also
My Journey Through Capital One CodeSignal Questions in 2026: What I Learned
How I Aced the BCG X CodeSignal Assessment in 2026
How I Passed the 2026 TikTok CodeSignal Online Assessment: Tips, Strategies, and Preparation Guide
How I Navigated the Visa CodeSignal Assessment and What I Learned
How I Cracked the Ramp CodeSignal Assessment and What You Can Learn
