My Real DoorDash HackerRank Questions From My 2025 Interview


My DoorDash OA had two questions and gave me 90 minutes. Both were mid-level in difficulty and focused on logical simulation and data-structure-driven optimization.
I am really grateful for the tool Linkjob.ai, and that's also why I'm sharing my entire OA interview experience here. Having an invisible AI interview assistant during the online assessment is indeed very convenient.
This article is part of the HackerRank series. If you're interested in other articles in this series, feel free to read: Microsoft HackerRank test, JP Morgan HackerRank test, Stripe HackerRank online assessment.
DoorDash Hackerrank Questions
Question 1: Team Formation
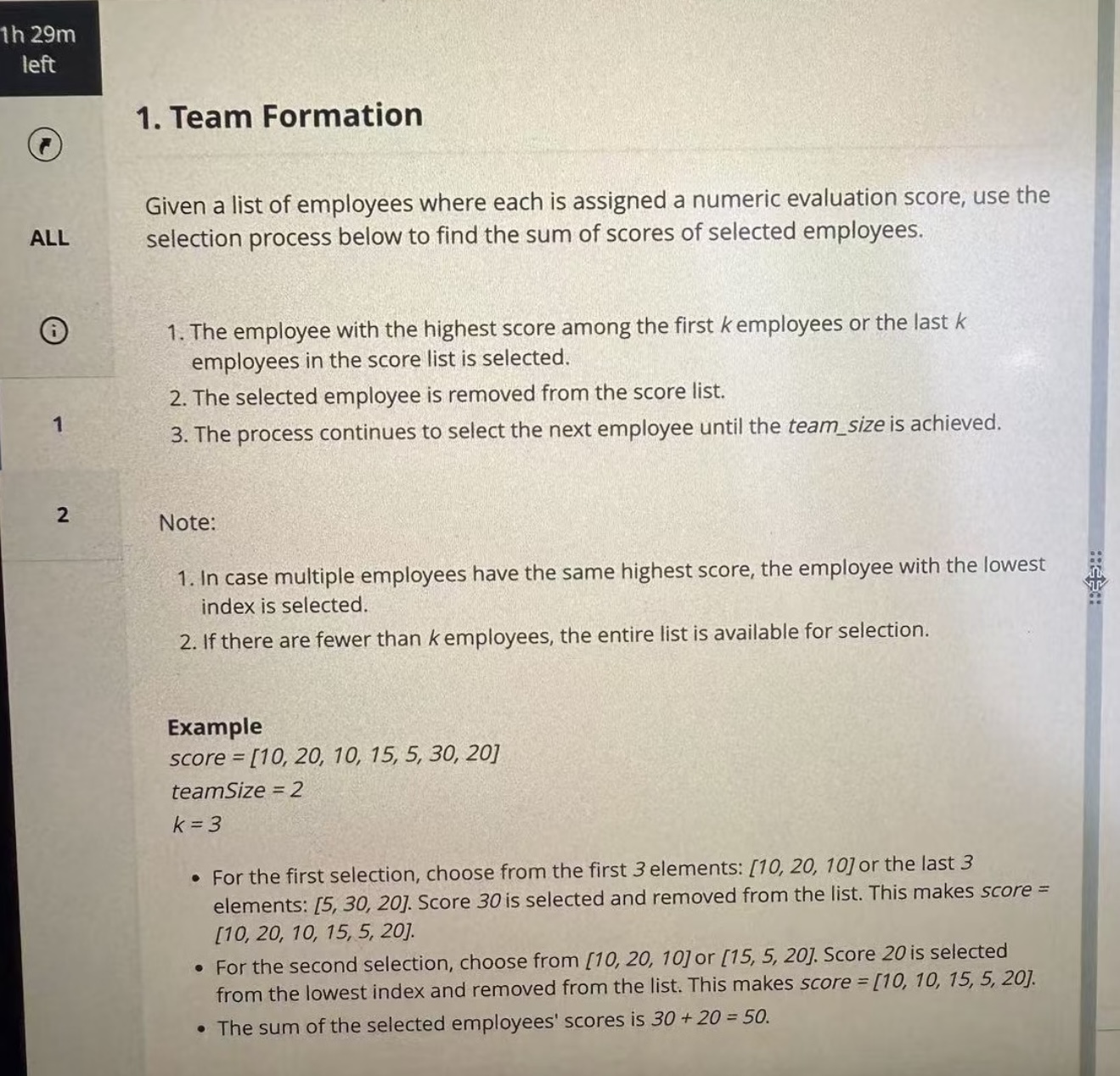
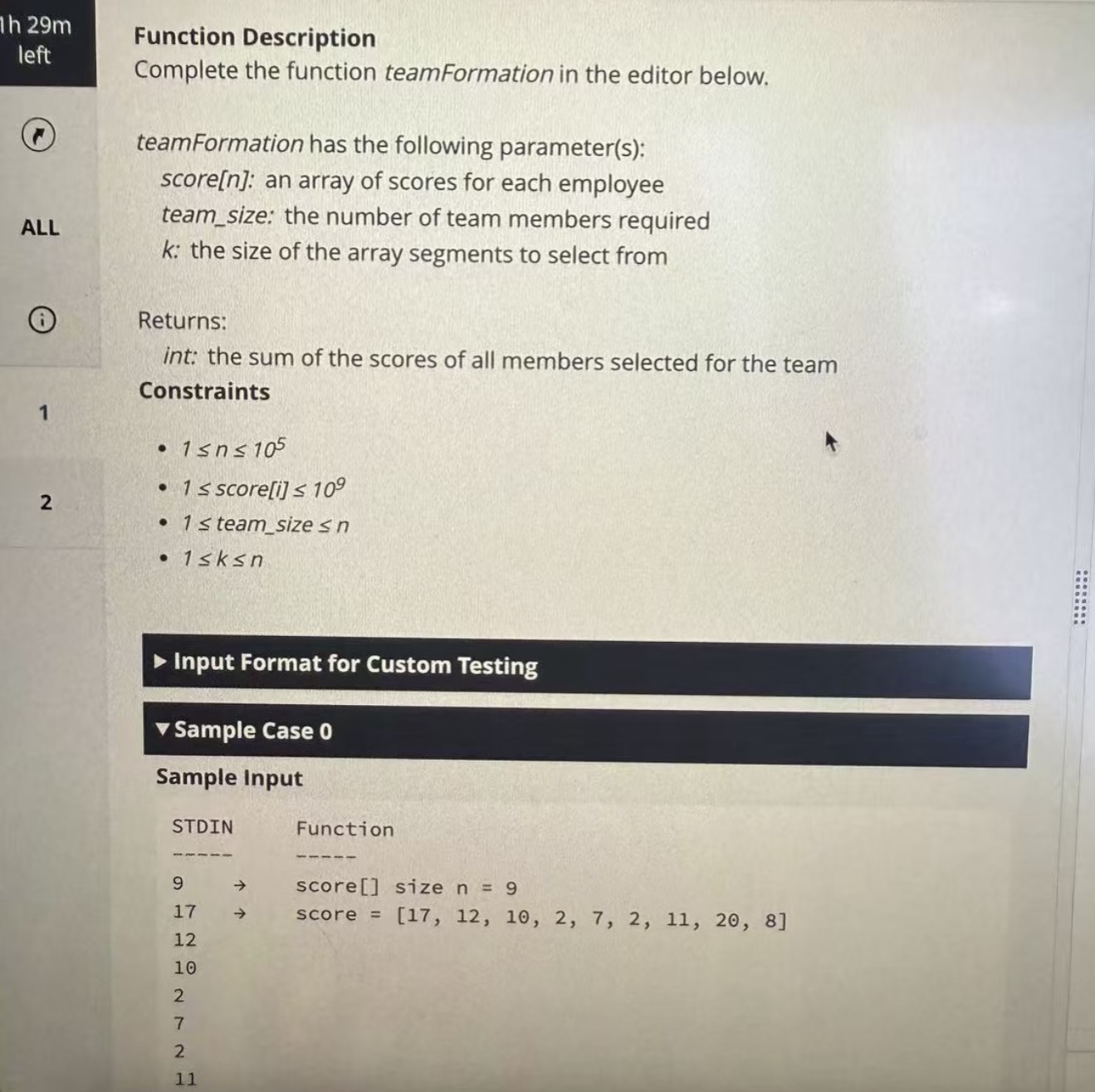
When I first saw this question, I broke the process down like this: each time a selection was made, the maximum value had to be chosen from the first k elements or the last k elements of the current list. If there were multiple maximums, the one with the smallest index had to be taken. After selecting a value, it had to be removed from the list, and the process repeated until team_size people were selected.
My initial thought was to simulate this directly with an array: slice the first k and last k segments, merge them, find the maximum with the smallest index, and then remove it from the original array. But since n could go up to 1e5, removing an element from a Python list (like list.pop(index)) takes O(n), and doing that team_size times would time out.
So I needed to optimize. I used two pointers to track the “valid range” of the current list (left pointer l and right pointer r, initially l=0 and r=len(score)-1). Each time I picked a candidate, the first k segment was [l, min(l+k-1, r)] and the last k segment was [max(r-k+1, l), r]. I scanned both segments, found the maximum value and the leftmost index of that maximum, and then moved l or r accordingly: if the chosen index was in the front segment, l moved forward; if it was in the back segment, r moved backward. This reduced each step to O(k). If k was extremely large (like 1e5), it could still be slow, but in practice team_size ≤ n, and k didn’t reach worst-case values. A further optimization would be to store both segments in a heap so extracting the maximum becomes O(log k).
My final steps looked like this:
Initialize l=0, r=len(score)-1, sum=0.
Repeat team_size times:
Determine the first k segment: start1=l, end1=min(l+k-1, r).
Determine the last k segment: start2=max(r-k+1, l), end2=r.
Scan both segments to find max_val and its index max_idx.
sum += max_val.
If max_idx ≤ end1, set l = max_idx + 1.
If max_idx ≥ start2, set r = max_idx - 1.
Return sum.
Example: score = [10, 20, 10, 15, 5, 30, 20], k=3, team_size=2
First round: l=0, r=6. First k is 0–2, last k is 4–6. Max is 30 at index 5 → sum=30, r=4.
Second round: l=0, r=4. First k is 0–2, last k is 2–4. Max is 20 at index 1 → sum=50, l=2.
Done → return 50.
Question 2

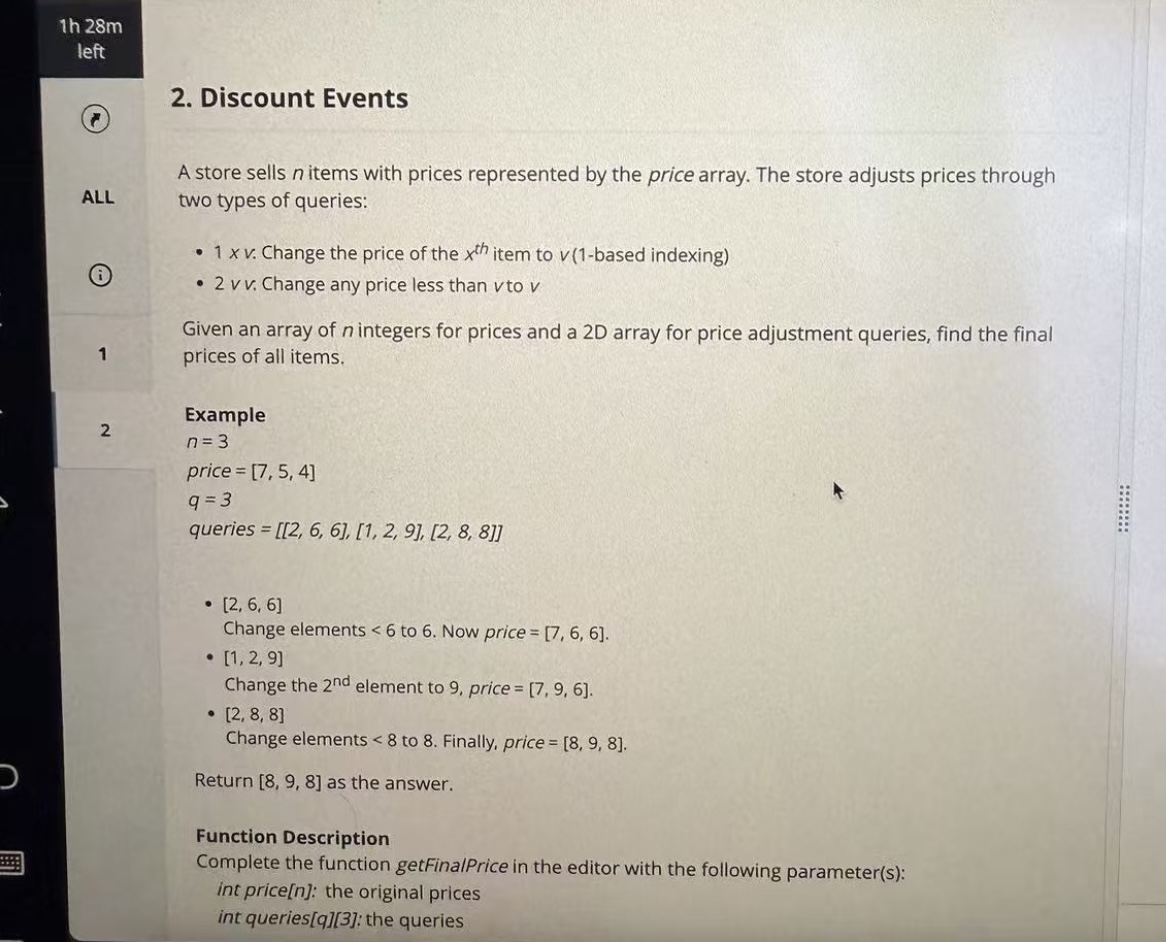
At first, I tried to “simulate every query.” For a type-2 query (set all values < v to v), I considered looping through the entire array and updating values. But with n up to 1e5 and a large number of queries, O(q·n) was clearly going to time out.
I got stuck for a moment, then realized: type-2 queries essentially impose a “global minimum floor.” But type-1 updates (set position x to v) interact with that floor. I had to track each position’s latest explicit update and the maximum floor value that applied after that update.
The correct approach was to process all queries in reverse:
Initialize a global current_min to track the minimum floor.
Create an array last_val to store each position’s “final updated value” (initially equal to the original price array).
Traverse all queries backward:
If it was type-2 with value v: update current_min = max(current_min, v).
If it was type-1 (x, v): if this position hadn’t been processed yet, set last_val[x-1] = max(v, current_min).
After processing all queries, apply current_min to all positions: last_val[i] = max(last_val[i], current_min).
Example:
price = [7, 5, 4]
queries = [[2,6,6], [1,2,9], [2,8,8]]
Backward traversal:
Third query: type-2, v=8 → current_min = 8.
Second query: type-1, x=2, v=9 → last_val[1] = max(9, 8) = 9.
First query: type-2, v=6 → current_min stays 8.
Final adjustment:
pos 0: max(7, 8) = 8
pos 1: already 9
pos 2: max(4, 8) = 8
Result = [8, 9, 8].
This reverse-processing approach runs in O(n + q).
I have to say, Linkjob AI is really easy to use. I used it during the interview after testing its undetectable feature with a friend beforehand. With just a click of the screenshot button, the AI provided detailed solution frameworks and complete code answers for the coding problems on my screen. I’ve successfully passed the test. Just as the HackerRank article “How to Cheat” states, the platform completely failed to detect me.
DoorDash HackerRank Assessment Format
Types of DoorDash HackerRank Questions
The DoorDash OA typically contained two coding questions, and occasionally there might be an extra simple SQL question (though I didn’t get one). The coding questions generally fell into these categories:
Logic simulation: The core was converting the problem’s rules into precise code logic, which tested reading comprehension and attention to detail.
Data-structure/optimization: These looked like simulation problems on the surface, but a brute-force approach would be too slow, so techniques like reverse processing, two pointers, or heaps were needed to optimize the time complexity.
Occasional string/array or greedy problems, but overall the focus leaned toward medium-level logic + optimization.
Format and Timing
Format: Pure coding questions on the HackerRank platform, supporting common languages such as Python, Java, and C++.
Duration: Normally 90 minutes.
Submission rules: Multiple submissions were allowed. The platform ran sample and hidden test cases in real time and showed whether they passed, but not the exact failing inputs.
Environment: Standard HackerRank interface with an editor, run button, and test input box.
Unique Aspects
A few things stood out to me about the DoorDash OA:
High information density: The instructions contained a lot of rules. For example, in Team Formation, things like “choose the max from the first k or last k, break ties by smaller index, delete the element, then update the range” required reading the description two or three times to get everything right. Missing one detail could break the whole solution.
Focused on engineering-oriented thinking rather than tricks: A problem like Discount Events didn’t require obscure algorithms, but it did test whether I could recognize that a brute-force solution would be too slow and then switch to a more efficient approach. That’s a very practical skill in real engineering work.
Detailed examples: The sample for Team Formation walked through every single step: what got chosen, how the list changed, and so on. I followed the sample manually first to confirm my understanding before coding.
Core Approaches I Used for the DoorDash OA
Break Down the Problem and Identify the Core Requirements
When I got the question, I didn’t start coding right away. I spent the first five minutes clarifying the core objective: what the problem was actually asking me to solve, what constraints were explicitly stated, what the possible input ranges were, and whether empty or extreme cases might appear. I summarized these key points in short comments so my thinking wouldn’t drift later and lead me into unnecessary work.
Build the Skeleton First, Then Fill In the Details
I began by setting up the core structure of the code. This included defining functions, handling input and output formats, and constructing the main loops or conditional structures to ensure the code would run. I then filled in the detailed calculations and logic step by step. Variables were initialized in advance and function calls for key steps were placed in order. This approach ensured the overall flow was complete even if I encountered difficulty with a specific detail.
Test Logic Continuously While Coding
While coding, I frequently created small test cases to verify each part of the logic. After completing a conditional statement or a loop, I manually checked a few simple inputs, paying special attention to boundary cases such as zero values or maximum parameters. This helped catch hidden errors early and prevented the situation where the full solution was finished but logic issues were discovered too late to fix individually.
DoorDash HackerRank Preparation Tips
Focus on Core Question Types and Practice Precisely
DoorDash OA mainly tested medium-difficulty logic simulation, array and string manipulation, and optimization problems. Extremely hard algorithm questions were generally unnecessary. I focused on problems that required careful reading to extract rules and those where a brute-force solution would time out and needed optimization. Examples include problems that can be optimized using two pointers, greedy strategies, or hash tables to reduce time complexity. Filtering for “Medium” difficulty questions on HackerRank with tags like “Arrays,” “Greedy,” and “Simulation” allowed me to practice 15 to 20 targeted problems efficiently.
Train Reading and Problem Decomposition Speed
The questions contained dense information, and misunderstandings could easily lead to mistakes. I spent three to five minutes per problem carefully reading the description, noting input-output requirements, constraints, and the core goal on scratch paper, and manually walking through the sample cases to confirm understanding before coding. This prevented starting the code with an incorrect interpretation and having to redo work.
Simulate the OA Environment and Practice Time Management
The actual assessment lasted 90 minutes for two questions. In practice, I simulated this rhythm with two similarly difficult problems under timed conditions to train reading, coding, debugging, and handling edge cases efficiently. A useful strategy was to first write a basic solution that passed the sample cases and then optimize for potential timeout issues. Familiarity with HackerRank’s editor, including quickly adding comments and running custom test cases, also reduced operational delays during the assessment.
Emphasize Code Readability and Debugging Skills
During practice, I developed the habit of adding concise comments indicating variable meanings and key logical steps. Printing intermediate results, such as loop variables and ranges, helped me debug more efficiently when test cases failed, allowing fast identification of issues compared to scanning the entire code.
FAQ
What was the process after passing the OA?
After I finished the OA, it took about two weeks for me to move to the next stage. The next step was three back-to-back interviews: two coding rounds and one behavioral round. After that, it took almost another month before I received the offer.
If I encountered a timeout during the assessment, should I prioritize optimizing or changing the approach?
I would first try to simplify the existing logic before considering a completely new approach. If a brute-force iteration caused a timeout on large test cases, I tried replacing nested loops with two pointers or hash tables to reduce time complexity. If the timeout persisted after optimization, I would revisit the problem constraints to see if there were overlooked strategies, such as greedy choices or reverse-processing, rather than blindly rewriting the code and wasting time.
Could I preview the test cases, and how did I troubleshoot failing ones?
I could not see the full hidden test cases, only the sample cases and any custom test cases I created. When a test case failed, my approach was to first check boundary conditions and then add comments or print intermediate results at key steps in the code. After resubmitting, I used the output logs to determine whether the issue was a misunderstanding of the logic or a missed detail in the implementation. This method was much faster than simply scanning the code for errors.
See Also
2026 Nvidia HackerRank Test: Questions I Got and How I Passed
How I Cracked 2026 Citadel HackerRank Assesment Questions
My IBM 2026 HackerRank Assessment: Real Questions & Insights
My 2026 MathWorks HackerRank Assessment Questions & Solutions
Questions I Encountered in 2026 Goldman Sachs HackerRank Test

© Copyright 2025 Linkjob.ai - All Rights Reserved.