How I cracked the Uber new grad interview in 2026

I’m a senior CS major at UC Berkeley, and during recruiting season I applied broadly to tech companies across the Bay Area, including Uber. Last week, I made it to the final onsite round for a SDE position and ended up receiving an offer. I often hear people say that Uber interviews are “easy”, but that really wasn’t my experience. The process was fast-paced, well-structured, and definitely challenging, so I wanted to share some of my takeaways and lessons learned.
First off, I have to recommend this real-time AI interview assistant. It can discreetly listen to interview audio, recognize on-screen problems, and provide real-time responses without being detectable. While it won’t carry you through the entire process—especially once you get to in-person interviews—it’s incredibly effective for OAs and phone screens. In a job market where landing a role is getting harder every year, this is honestly an investment that pays for itself.
Preparation for the Uber New Grad Interview
The entire application process started in January and lasted about 6 weeks, with roughly one stage moving forward each week. Uber’s interviews were much harder than I had expected, and honestly, what I learned from the interviews was more valuable than grinding tons of LeetCode problems.
1. OA (70 minutes):
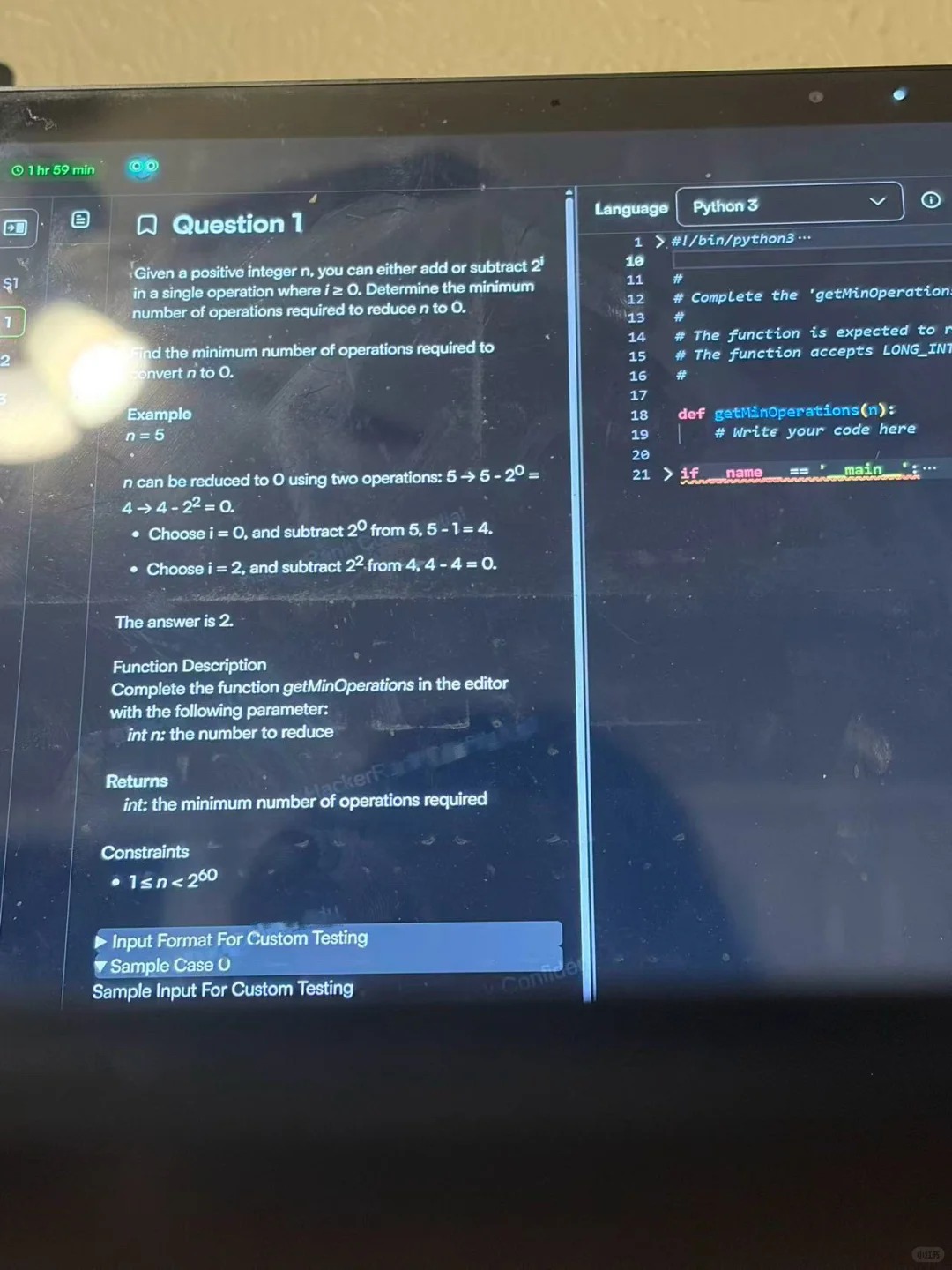
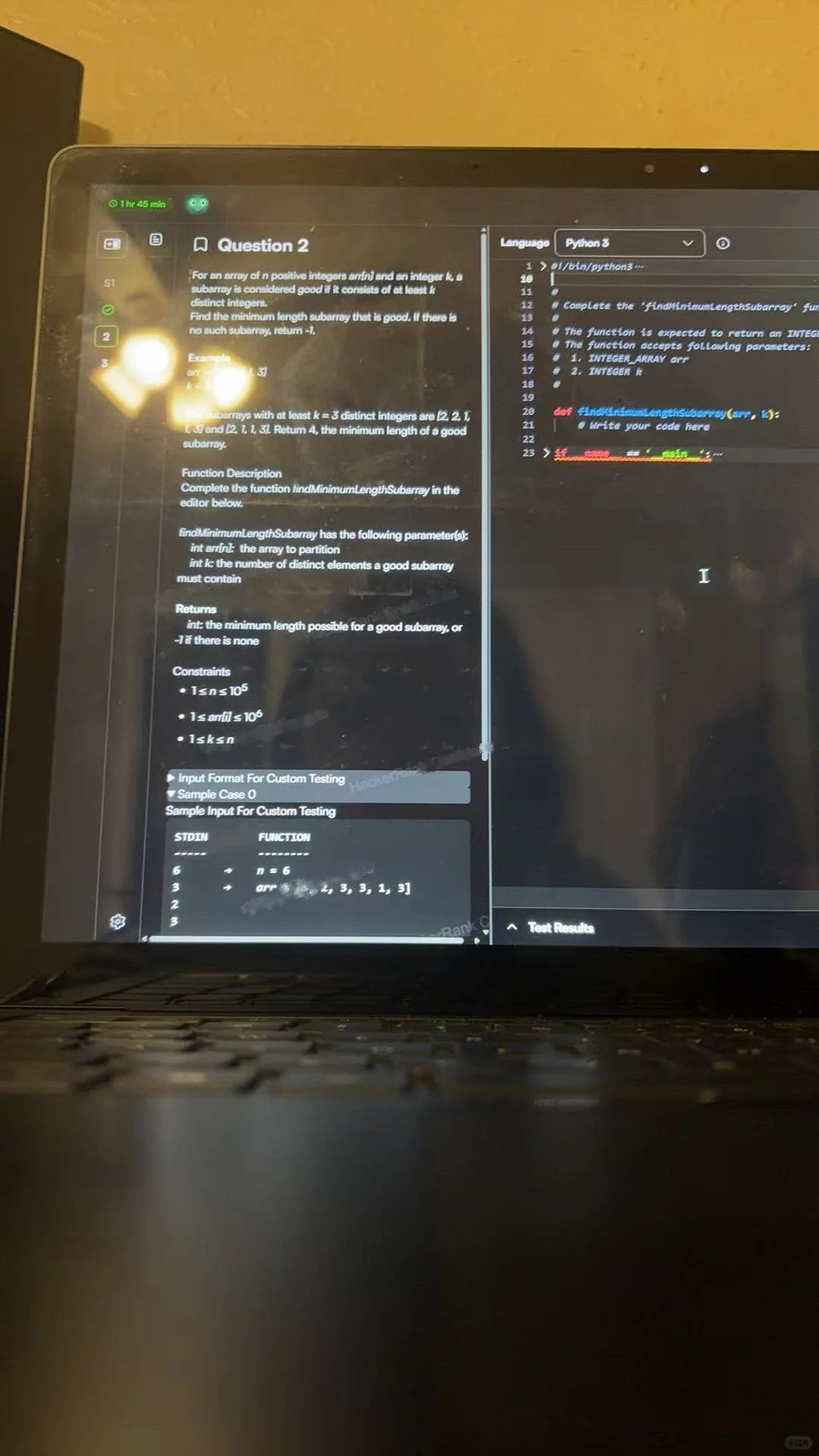
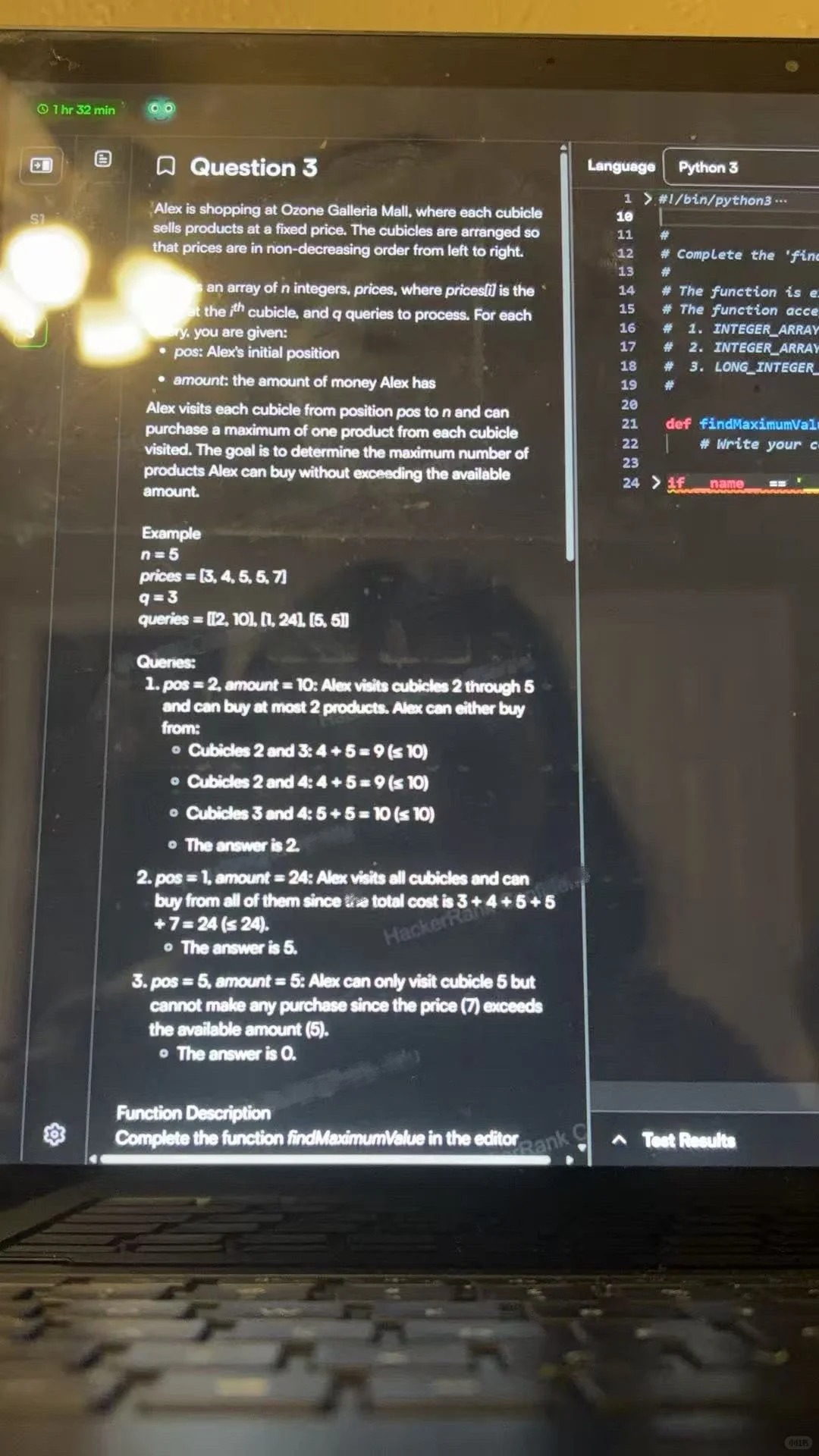
You’re given 70 minutes to complete 3-4 coding questions. In my experience, 1-2 were relatively Easy, 1 was Medium, and 1 was Hard—but the difficulty doesn’t necessarily increase with the question number. For example, my Hard problem was actually question 3. Time felt extremely tight. My recommendation is to knock out the Easy and Medium problems first to secure baseline points, then spend the remaining time tackling the Hard one. Getting stuck on a hard problem too early can easily throw off your mindset and leave you short on time. The problem types themselves are fairly classic, so it’s worth doing some targeted prep in advance (on LeetCode, you can often find very similar or even identical questions).
2. Phone Screen (~45 minutes):
The interviewer was a Senior engineer with a very straightforward style. After brief introductions, we jumped straight into the interview.
The interviewer asked me to walk through one of my projects from Amazon in detail—covering the background and motivation, design decisions, technology choices, challenges and how I addressed them, as well as results and post-mortem reflections. Throughout the discussion, there were constant follow-up questions. The pressure was relatively high: the questions were granular and the pace was fast.
Before this round, you really need to thoroughly review and internalize your resume. Make sure you can explain your projects clearly and logically, and be ready for deep dives from multiple angles. If you’re underprepared, it’s easy to get stuck at this stage. You’ll usually hear back within a week on whether you’re moving on to the next round.

3. Onsite (5 rounds, ~60 minutes each)
A total of 5 rounds, with a 30-minute break between each. The interviewers were professional, and the overall atmosphere was friendly.
Round 1 (Coding):
A standard algorithms and data structures problem. The difficulty was medium to high. They evaluated whether I could clearly communicate my thought process and write clean code under pressure. (Comparable to medium-to-hard LeetCode problems.)
Rounds 2 & 3 (System Design):
These were the hardest and most critical rounds. They involved system design, technical trade-offs, scalability, failure handling, and more. Some questions were extended based on my past project experience.
The prompt I received was: Design a real-time surge pricing engine.
They wanted me to design a system that ingests millions of GPS location data points per second, calculates real-time supply and demand across an entire city, and outputs a surge multiplier every 30 seconds.
The interviewer described the requirements like this:
"We need a system that can compute dynamic pricing for each hexagonal region in a city in near real time. It should consider current ride requests, available drivers, historical demand patterns, as well as external factors like weather or large events. Prices should be updated at least every 60 seconds."
My instinct was to immediately start drawing an architecture diagram, but I stopped myself in time—because the first step is really to clarify the requirements (and in hindsight, this step was absolutely critical).
I first clarified the functional requirements:
The system must calculate surge multipliers by geographic region.
It must ingest real-time supply data (driver GPS locations) and demand data (ride requests).
The multiplier should reflect current conditions, not rely solely on historical averages.
The output must directly integrate with the rider-facing pricing service.
Then I clarified the non-functional requirements:
Latency: The multiplier must be recomputed within 60 seconds (P99 < 5s for the pipeline).
Scalability: Support 500+ cities globally and over 10 million active users.
Availability: 99.99% uptime. If surge calculation fails, default fallback is 1.0x (no surge).
Accuracy vs. speed: Speed is prioritized. A slightly stale multiplier is better than no multiplier at all.
Drawing from my previous internship experience, I also asked: “How should the system degrade gracefully if it fails?”
My takeaway is, proactively thinking about failure scenarios is one of the easiest ways to demonstrate strong system-level thinking.
The second part can really rank candidates. The night before the interview, I had deliberately studied Uber’s open-source H3 geospatial indexing library. I opened with “We’ll use Uber’s proprietary H3 hexagonal indexing system, set at resolution 7, so each hexagon covers about 5 square kilometers. Each hex has a unique 64-bit ID. This is important because hexagons have uniform adjacency distances—unlike square grids, which suffer from diagonal distortion—so our demand diffusion calculations will be more accurate.”
Then I explained the core components:
H3 Hex Mapper: Converts raw latitude and longitude into H3 hex IDs, with sub-millisecond latency.
Supply & Demand Counters: Sliding-window counters (last 5 minutes), stored in Redis and keyed by hex ID.
Surge Pricing Calculator: An Apache Flink streaming job that runs every 30–60 seconds, reads from both counters, and computes the surge multiplier.
Pricing Cache: The output is written to a low-latency Redis cluster for consumption by the pricing service.
After we moved into the third part, the interviewer started drilling into the details: “So how does this surge pricing calculator actually compute the multiplier?”
I first gave a very simple formula:
surge_multiplier = max(1.0, demand_count / (supply_count * target_ratio))
Then I immediately added, “That’s just the baseline version. In a real system, we’d layer in several additional pieces of logic.”
First, neighboring hex aggregation. For example, if Area A has zero drivers but the adjacent Area B has 10, we shouldn’t show a 5× surge in Area A. We’d use something like kRing(hex_id, 1) to merge supply data from the surrounding six neighboring hexes.
Second, historical baseline normalization. Manhattan on a Friday night is always busy. The model needs to distinguish between a “normal Friday” and a “Taylor Swift concert Friday.”
Third, external signals. We’d ingest signals from a weather API, an events calendar, and even Uber’s own map and traffic data.
Then the interviewer asked about failure scenarios, “What happens if the Flink job crashes halfway through?”
My answer was:
Stale-cache fallback: Redis keys are set with a TTL of 120 seconds. If a new multiplier isn’t written in time, we keep serving the last known value. Riders may see slightly stale surge pricing—but that’s far better than a hard outage or no surge logic at all.
Dead Letter Queue (DLQ): Failed Flink events are sent to a Kafka dead-letter topic, which also triggers alerts so the on-call engineer can investigate.
Circuit breaker: If the surge pricing pipeline is down for more than three minutes, the pricing service automatically falls back to 1.0× (no surge). This protects riders from seeing an outdated or artificially inflated price due to a system failure.
This kind of storytelling turns a static architecture diagram into something that feels alive in the interviewer’s head—a real system, running in production.
Round 4 (Hiring Manager):
This round leaned more toward soft skills and alignment with the JD. It covered a lot of the classics—org and product overview, team goals, career trajectory, strengths and weaknesses, and examples of collaboration and problem‑solving from school or past roles. Since we had already gone pretty deep on my projects earlier, this round actually felt quite smooth.
Round 5 (Culture Fit):
This one focused heavily on behavioral questions, teamwork, and alignment with Uber’s values. It’s a round you absolutely can’t sleep on—no matter how perfect your coding interviews are, failing culture fit can still get you rejected.
The question I got was, “Can you share a time when you disagreed with your team on a technical decision?”
I talked about pushing a migration from a polling-based architecture to an event-driven one at Amazon, and I framed it using the STAR method:
"Our notification system was polling the database every five seconds, which caused frequent CPU spikes. I proposed moving to a Kafka-based event streaming architecture and built a proof-of-concept in three days. The POC showed a clear latency comparison: ~5 seconds on average with polling versus ~200 ms with events. I also addressed the team’s concerns about Kafka’s operational complexity. In the end, the team adopted the event-driven approach, and CPU usage dropped by 60%."
The takeaway for me was that data beats opinions. Any technical disagreement should be resolved with prototypes and benchmarks, not slide decks.
I felt pretty good about how I answered this round. That said, in hindsight, even a great behavioral interview can’t save a shaky system design.
Overall, the onsite was intense—five rounds back-to-back is a real test of stamina and focus, and it’s definitely exhausting. That said, the interviewers were generally very nice and tried to create a relaxed, conversational atmosphere. For the tech rounds, you need solid fundamentals and the ability to explain your thinking clearly. And every project on your resume needs to stand up to deep, repeated scrutiny.
Key Takeaways
Overall, Uber interviews are not something you can take lightly. If you want a strong outcome, here’s my advice:
Obsess over edge cases. Beyond the happy-path design, spend real time preparing for failure modes, regulatory constraints, and multi‑region complexity.
Read Uber’s engineering blog—cover to cover if you can. Uber openly shares real architectural decisions around things like H3, Ringpop, and Schemaless. These are free, first‑party resources—there’s no reason not to mine them as deeply as possible.
Practice high‑pressure follow‑ups. Vague “design a system” prep won’t save you when the interviewer starts throwing curveballs. Use places like PracHub and Glassdoor to study company‑specific follow‑up patterns.
Record yourself explaining. Talking through a diagram in front of a mirror is very different from being challenged live. I now record mock interviews and replay them to see exactly where I stumble or get hand‑wavy.
Trust your prep, you can do this, too. Go for it!
FAQ
How many months did I prepare for the Uber new grad interview?
I spent about 1 months preparing. I studied every day for one to two hours. I focused on coding, system design, and behavioral questions. Consistency helped me more than cramming.
What was the hardest part of the interview process?
The system design round challenged me the most. I had to think on my feet and explain my ideas clearly. I practiced with mock interviews and learned to break big problems into smaller steps. You can use Claude Opus to guide your programming—it’s extremely strong when it comes to writing and refactoring code.
Do I need a referral to get an interview at Uber?
A referral helps, but it is not required. I applied online and reached out to alumni for advice. Networking opened doors for me. I recommend building real connections, not just asking for referrals.
What resources did I use for system design prep?
I used "Understanding Distributed Systems" and watched YouTube videos on system design basics. I also joined Discord groups for peer discussions. Practicing with friends made a big difference.
How did I handle nerves before the interview?
I took deep breaths and reminded myself of my preparation. I did a quick review of my notes and practiced explaining my thought process out loud. Staying calm helped me think clearly.
See Also
My Uber HackerRank OA Experience in 2025 and Real Questions
How I Should Approach Common Uber CodeSignal Questions in 2025
How I Nailed My NVIDIA New Grad Interview in 2026

© Copyright 2025 Linkjob.ai - All Rights Reserved.