My 2026 HSBC Codility Test: 3 Real Coding Questions & Answers


HSBC Codility Test Questions
I just interviewed for the HSBC Quant position. The coding part of the OA was done on Codility, with a total of three questions. The difficulty level was on the easier side of medium, and I had 60 minutes to complete them. Below, I’ll share the three questions I got and my thought process for solving each one.
I’m really grateful to Linkjob.ai for helping me pass my interview, which is why I’m sharing my OA questions and experience here. Having an undetectable AI real time interview assistant indeed provides a significant edge.
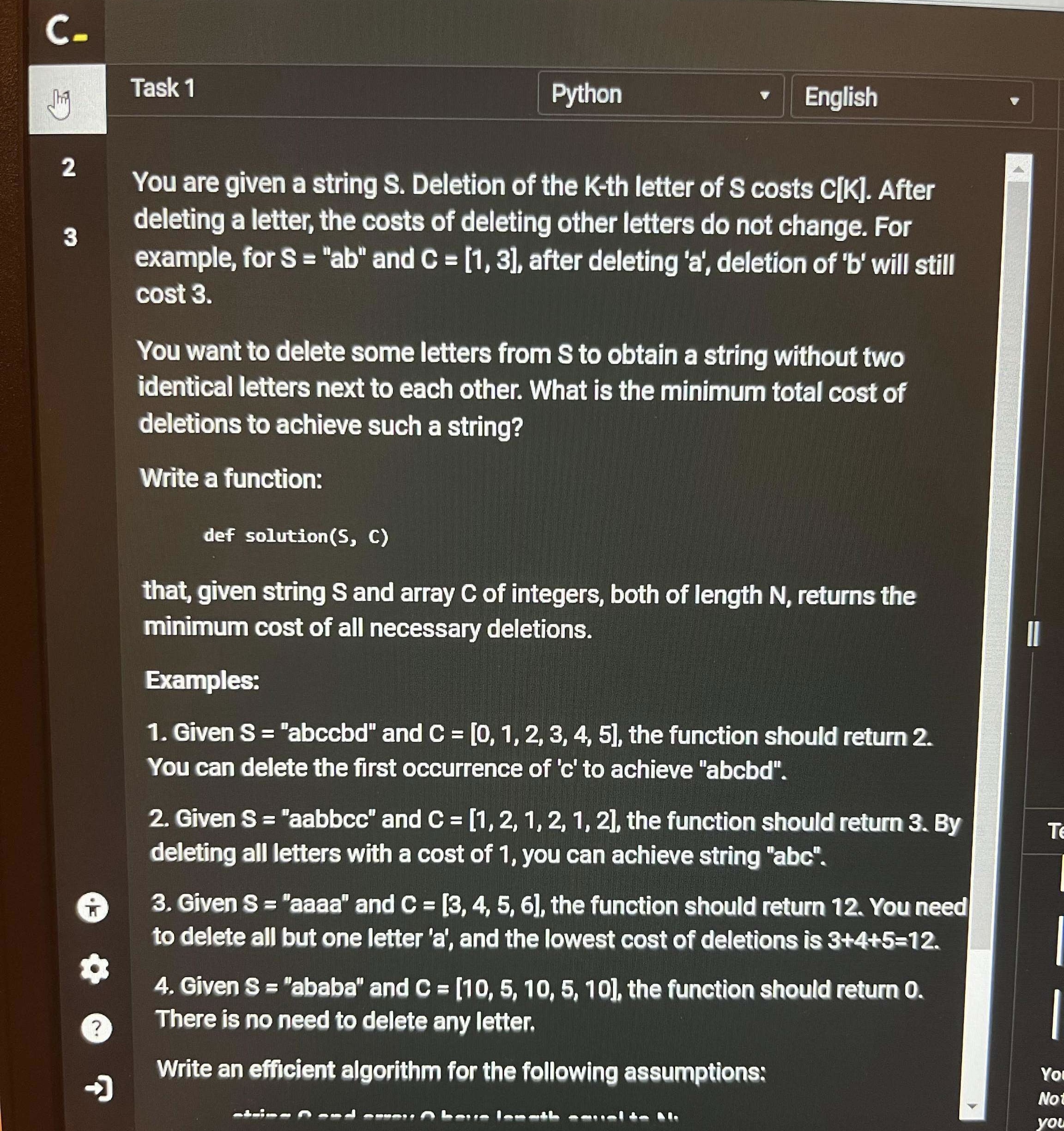
Task 1
Task 1: My Approach
The core requirement was to remove adjacent duplicate characters from a string while minimizing the deletion cost. My approach therefore focused on handling groups of consecutive identical characters.
For example, if we had a string like "aabbbcc", we needed to keep only one character from each group and delete the rest. Specifically, deleting the ones with the lowest costs to minimize the total.
Here’s how I approached it step by step:
I traversed the string and split consecutive identical characters into groups.
For "aabbbcc", that became ["aa", "bbb", "cc"].
For each group, I calculated the total cost of all characters, then subtracted the maximum cost within that group (since I kept the most expensive one and deleted the rest).
Finally, I summed up all the “(group sum - group max)” results to get the minimum total deletion cost.
For example, in sample case 2 "aabbcc", the groups were ["aa", "bb", "cc"]. The total cost for each group was 1+2=3, and the max cost was 2. So the total deletion cost was (3−2) + (3−2) + (3−2) = 3, which matched the sample output.
I implemented it using a simple traversal or two-pointer approach. The overall time complexity was O(N), very efficient.
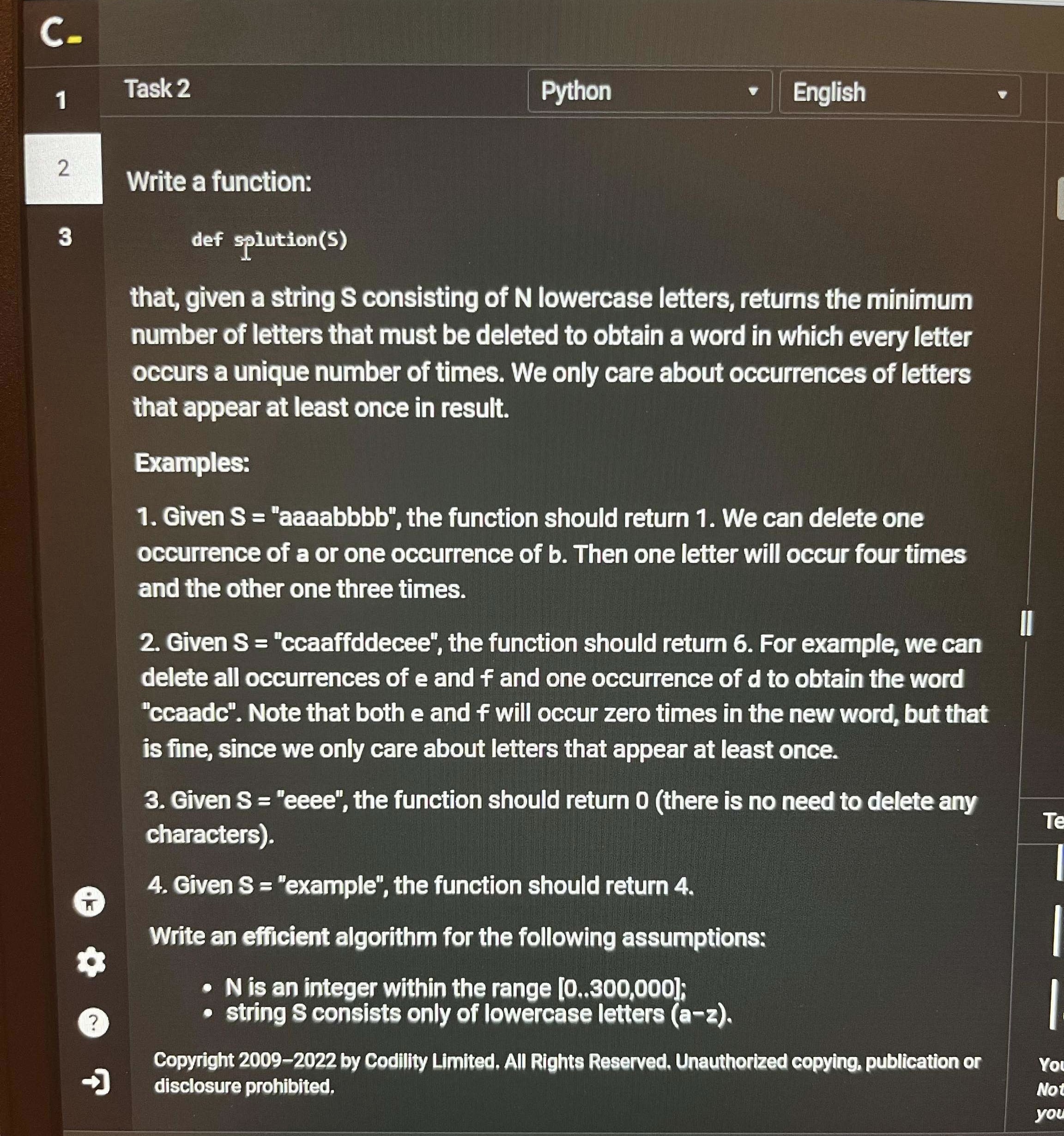
Task 2
Task 2: My Approach
The key challenge here was to make sure every character frequency was unique. My strategy was to first count the frequency of each character, then adjust the counts to remove duplicates. Here’s what I did:
I used a dictionary to count the occurrences of each character and got a list of frequencies.
Then, I kept a set to track which frequencies had already been used.
As I iterated through the list, whenever I found a frequency already in the set, I kept reducing it by 1 until I reached a number that wasn’t in the set (or 0, meaning that character was completely removed).
Each reduction meant deleting one character, so I incremented the total deletions accordingly.
After processing all characters, the total number of deletions was my answer.
For example, in "aaaabbbb", the frequencies were [4, 4]. I added the first 4 to the set. For the second 4, since it already existed, I reduced it to 3, deleted one character, and added 3 to the set. The total deletions were 1, exactly as expected.
I had to be careful when the frequency reached 0, as that meant the character no longer appeared in the result. The time complexity was easily acceptable for N = 3e5, since each frequency was processed at most once.
Linkjob AI worked great and I got through my interview without a hitch. It’s also undetectable, I used it and didn't trigger any HackerRank detection.
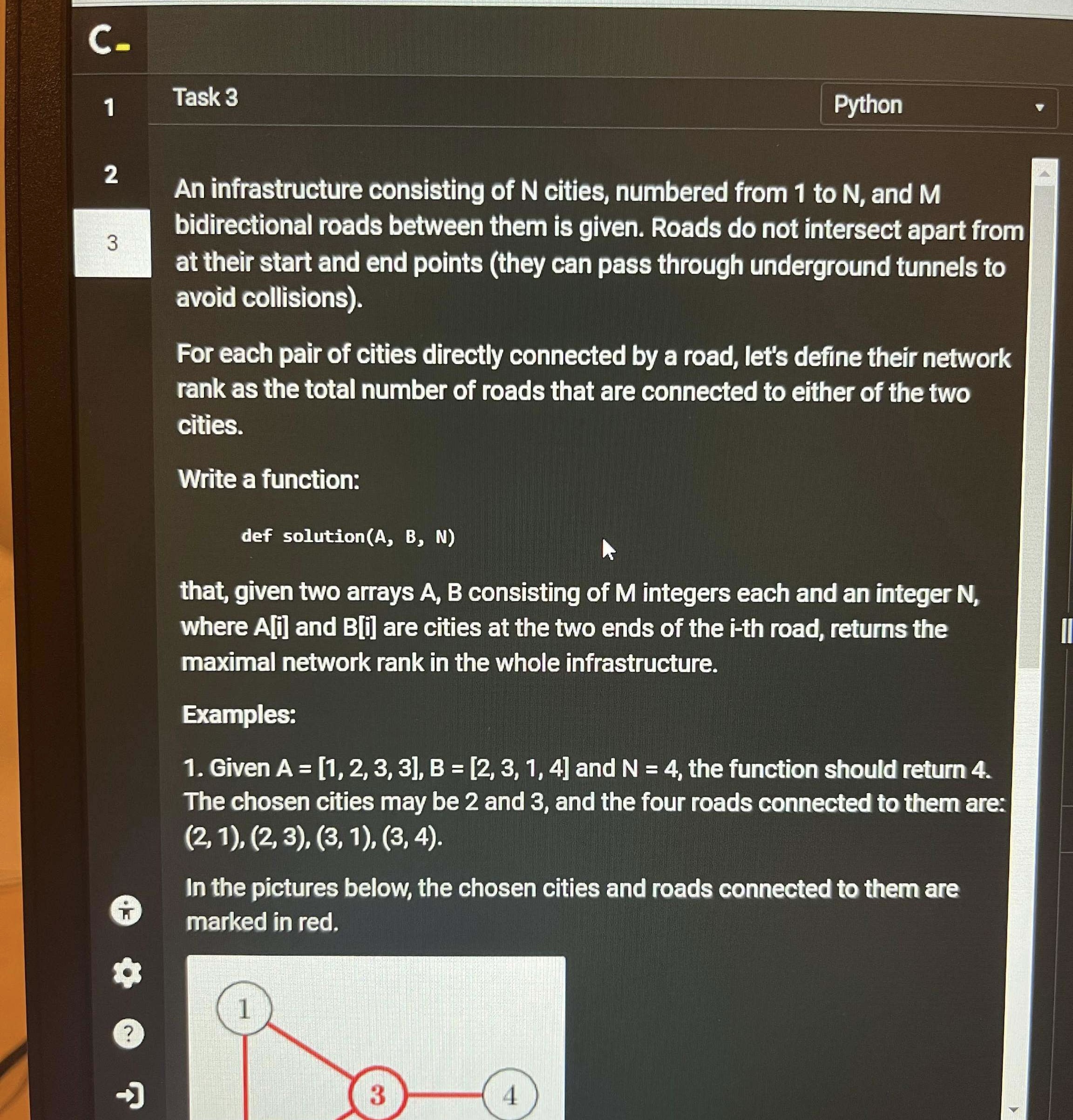
Task 3
Task 3: My Approach
This one was about finding the maximum network rank. The definition was straightforward: the network rank between two directly connected cities was the sum of their individual road counts, minus one (to avoid double-counting the direct road between them).
Here’s how I solved it:
First, I counted how many roads each city had. Basically, I built a degree array where degree[i] represented the number of roads connected to city i.
Then, for every road connecting two cities u and v, I calculated their combined network rank as degree[u] + degree[v] - 1.
I tracked the maximum of all these values.
If there were no roads at all (M = 0), the maximum rank was simply 0.
Taking sample input 1 as an example:
A = [1,2,3,3], B = [2,3,1,4]
The degrees were:
City 1 → 2 (roads 1–2, 3–1)
City 2 → 2 (roads 1–2, 2–3)
City 3 → 3 (roads 2–3, 3–1, 3–4)
City 4 → 1 (road 3–4)
Then, for each road:
1–2 → 2 + 2 − 1 = 3
2–3 → 2 + 3 − 1 = 4
3–1 → 3 + 2 − 1 = 4
3–4 → 3 + 1 − 1 = 3
The maximum rank was 4, which matched the sample output.
I found this one quite intuitive, just a matter of counting and combining. The time complexity was O(M + N), which worked perfectly within the constraints.

HSBC Codility Test Format
Question Types
HSBC’s Codility test mainly consists of programming and algorithm problems, focusing on logic, data structure usage, and basic algorithm design common in real engineering scenarios. The overall difficulty is medium. The main categories include:
String Processing: Operations on strings with duplicate characters. The key is grouping consecutive or non-consecutive characters, iterating through them, and applying greedy strategies.
Hashing and Counting: Problems based on character or number frequency, involving deduplication and frequency adjustments. Efficient state tracking with hash tables is required.
Basic Graph Theory: Simple graph structures that test node degree counting, edge traversal, and basic metric calculations, essentially combining arrays and hash tables.
Other Common Types: Occasionally includes array manipulations or simple dynamic programming. Overall, the focus is on intuitive logic and efficient implementation, with complex algorithms rarely appearing.
Core Assessment Points
The Codility test evaluates engineering mindset and fundamental coding skills. Key assessment dimensions include:
Problem Decomposition: Ability to quickly understand core requirements and convert abstract problems into actionable steps.
Data Structure Choice: Selecting appropriate tools for the scenario to optimize time and space complexity.
Logical Rigor: Handling edge cases such as empty inputs, single elements, or repeated extreme values.
Coding Efficiency: Translating ideas into clean, bug-free code within limited time, emphasizing variable naming, logical structure, and readability.
Overall, HSBC’s Codility test emphasizes practical coding ability rather than purely algorithmic difficulty. The goal is to identify candidates who can efficiently solve foundational logic problems relevant to real business tasks.
HSBC Codility Assessment Preparation Strategies
I spent two and a half weeks preparing for HSBC’s Codility test, focusing on exercises aligned with HSBC’s question types and simulating the real exam pace. I completed all three problems within the time limit. Here’s my actual study plan and resource selection.
My Study Plan
I didn’t just grind random problems; I divided preparation into three phases, each with clear objectives.
Phase 1: Foundation Building
30 mins for Data Structure Review: Using Python, I spent 30 minutes each morning reviewing lists, dictionaries, and sets.
1 hour for Basic Algorithm Practice: Each day I solved 2–3 simple problems, focusing on turning problem-solving ideas into code rather than speed.
30 mins for Mistake Review: I kept a notebook for errors and tricky points to quickly review before the exam and avoid repeating mistakes.
Phase 2: Targeted Practice
In the second week, I focused on one type of problem per day until I knew exactly how to start each problem.
1.5 hours for Subject-Specific Practice: I tackled 3 medium-difficulty problems per topic, summarizing reusable solution templates.
30 mins for Template Summarizing: I documented templates for each problem type.
30 mins for Code Optimization: I optimized redundant code. For example, replacing multi-loop frequency counts with Counter(), reducing 5 lines to 1 and lowering complexity. This step is crucial because HSBC’s system checks time complexity and simpler code is easier to debug.
Phase 3: Mock Sprint
Five days before the test, I simulated real exam conditions to practice time management and problem-solving under pressure.
1.5 hours for Full Mock Tests: I used Codility and LeetCode, following the test rules exactly.
30 mins for Post-Mock Review: After each mock test, I reflected on what went well and what could be improved.
Recommended Practice Resources
I tried many resources and kept only the most useful ones, those closely aligned with HSBC’s question types or simulating real test conditions.
Codility Official Website (Must-Use):
Practiced almost daily the week before the test. The platform mirrors HSBC’s system, checking time complexity and covering edge cases.
Recommended Sections:
“Practice” → “Lessons”: Focused on Lesson 1 (Iterations), Lesson 2 (Arrays), Lesson 4 (Counting Elements), Lesson 6 (Sorting).
“Practice Tests” → “General Coding Assessment”: Did “Codility Demo Test” and “Practice Test 1” (Medium), simulating 3 problems in 60 minutes.
LeetCode (Complementary Practice):
Searched for problems matching HSBC tasks.
Recommended method: filter by tags (“String,” “Hash Table,” “Graph”) and difficulty (“Easy” or “Medium”), solving 2–3 per day. Also searched “HSBC OA past questions” to find original problems shared by candidates.
Supplementary Materials: Fill Knowledge Gaps
Cracking the Coding Interview (6th Edition): Focused on Chapter 1 (Arrays & Strings) and Chapter 4 (Graphs) for relevance to HSBC problems. Strengthened understanding of string handling and graph relationships.
Past Exam Questions: Familiarize with HSBC’s Style
Glassdoor: Main source for real past problems with explanations and code. Practicing these saved time in the actual test.
LinkedIn: Connected with an HSBC tech team member for insider tips.
HSBC Codility Coding Tips
In the HSBC Codility test, solving problems efficiently, ensuring code quality, and debugging quickly are key to passing. Below are practical tips directly tailored to the test, covering problem-solving, code quality, and debugging strategies.
Problem Solving
Before coding, clearly outlining the logic and avoiding blind coding is crucial for efficiency.
Translate Requirements into Actionable Steps
After reading the problem, break down the requirements into concrete, executable steps. These can be written as code comments.
Validate Steps with Example Cases
After outlining steps, check the logic using the sample inputs provided. For example, in the “aabbcc” case, after grouping, each group’s total cost is 3, maximum cost is 2, and the total deletion cost is (3-2)×3=3, matching the example. If results differ, adjust the steps before coding to avoid building on incorrect logic.
Pre-Identify Edge Cases
HSBC often tests boundary scenarios. Identifying them early reduces debugging later. Common edge cases include:
String problems: empty string (s=""), single character (s="a"), all repeated characters (s="aaaaa").
Graph problems: zero edges (M=0), nodes connected by only one edge.
Counting problems: all elements with the same frequency (e.g., "aabbcc"), or an element appearing once.
Edge checks can be added directly in the code. For instance, if M=0 in a graph problem, return 0 immediately.
Code Quality
Code should be correct, readable, and efficient, aligning with HSBC’s assessment standards.
Use Self-Explanatory Variable Names
Avoid vague names like a, b, or x. Clear names reduce debugging effort and improve readability.
Leverage Simple Built-In Functions
Use basic built-in functions in Python to simplify code and reduce errors, but avoid overly complex or obscure functions.
Control Time Complexity
Problems generally require O(N) or O(N log N) solutions. Avoid O(N²) or higher to prevent timeouts.
Debugging
With limited time, targeted strategies are essential to quickly locate and fix issues.
Print Intermediate Results Temporarily
Insert print statements at key steps to verify data matches expectations.
Test with Custom Small Cases
Beyond the sample inputs, create small test cases to verify correctness.
Check Boundary Indexes First
Index errors are common in string and array problems.
Allocate Time Reasonably
If stuck on a bug for more than 10 minutes, move to another problem and return later. HSBC scores based on total points, so don’t risk leaving other problems unfinished. Switching tasks may also clarify your thinking.
Final Check Before Submission
In the last 5 minutes, quickly verify:
All boundary cases are covered (empty inputs, extreme values).
Variable and function names are spelled correctly.
Core calculations are complete (no missing terms or conditions).
A quick final check can prevent unnecessary points lost due to basic mistakes.
FAQ
Are there any parts of HSBC’s online assessment besides the Codility test?
Yes, there are. There’s also a personality test and a video interview (VI). The personality test takes around 15 minutes, and some questions are actually asking the same thing in different ways, so it’s important to keep your answers consistent. As for the VI, you’ll need to record yourself answering three timed questions.
How many rounds are there after the OA?
I had two video interviews after the OA, each lasting about 30 minutes. Both focused on my project experience and the specific role, and I felt they really emphasized role fit.
Is the HSBC interview process fast?
Mine actually moved pretty quickly. I got the OA soon after submitting my resume, and then they scheduled the next round just two or three days later. I think it mainly depends on how urgently the team needs people. The timeline probably varies by role.
See Also
My Secret Hacks For Beating HackerRank Proctoring and Detection
How I Passed 2026 Microsoft HackerRank Test on My First Try
2026 Update: My Stripe HackerRank Online Assessment Questions

© Copyright 2025 Linkjob.ai - All Rights Reserved.