How I Passed the OpenAI System Design Interview in 2026

(System design Case Problem)
I still remember the nerves I felt walking into the OpenAI system design interview. I quickly realized that most candidates don’t fail due to lack of technical skill, but because of open-ended questions, time pressure, and difficulty structuring complex ideas in real time. What helped me wasn’t memorizing answers—it was learning how to keep my thinking structured under pressure.
Early on, I noticed that OpenAI heavily favors real-time, spatial-query-driven system design problems, similar in structure to classic Uber or Lyft scenarios. The questions required reasoning about real-time updates, strict latency constraints, and consistency trade-offs at scale. These problems are effective because they expose whether a design truly holds up under uneven demand, rapid churn, and regional failures—not just whether it works on paper.
During interviews, I use Linkjob.AI as a AI interview copilot, providing real-time key system design concepts. In high-pressure moments—when details like partitioning strategies, consistency models, or failure scenarios threaten to slip my mind—it instantly presents structured answers and decision frameworks, allowing me to regain clarity almost instantly. Without scrambling to recall specifics, I could focus on articulating trade-offs, simulating constraints, and clearly communicating reasoning. In practice, it functioned like an invisible, always-ready encyclopedia of system design—integrating common test patterns, edge cases, and interviewer expectations validated by thousands of users, continuously refined and optimized.

Because the tool operates transparently, I could focus on what truly matters: asking clarifying questions, articulating trade-offs clearly, and conveying my reasoning in a structured manner. Reflecting on the entire process, solid preparation, the right mindset, and the ability to reliably recall core concepts under pressure collectively formed a decisive advantage—precisely why I firmly believe you can also succeed in this interview.
OpenAI System Design Interview Process — Content Overview
Topic One: OpenAI System Design Interview — Real Questions
A deep dive into real system design questions commonly asked in OpenAI interviews, including LLM-powered systems and large-scale infrastructure problems.
Topic Two: Interview Stages Overview
A high-level breakdown of the OpenAI interview process, from initial screening to final system design rounds, and what each stage is actually evaluating.
Topic Three: What to Expect and How to Prepare for the OpenAI System Design Interview
An inside look at how OpenAI frames system design interviews, what interviewers focus on, and how to prepare efficiently without over-studying.
Topic Five: Preparation Tips and Strategies
Practical preparation advice, study resources, and structured practice routines that helped me stay calm and perform consistently under pressure.
Topic Six: Final Takeaway
The core lessons from the entire interview process, including why structure matters more than memorized answers—and how to approach system design interviews with confidence.
Topic One: OpenAI System Design Interview: Real Questions
(Four-Step System Design Framework)
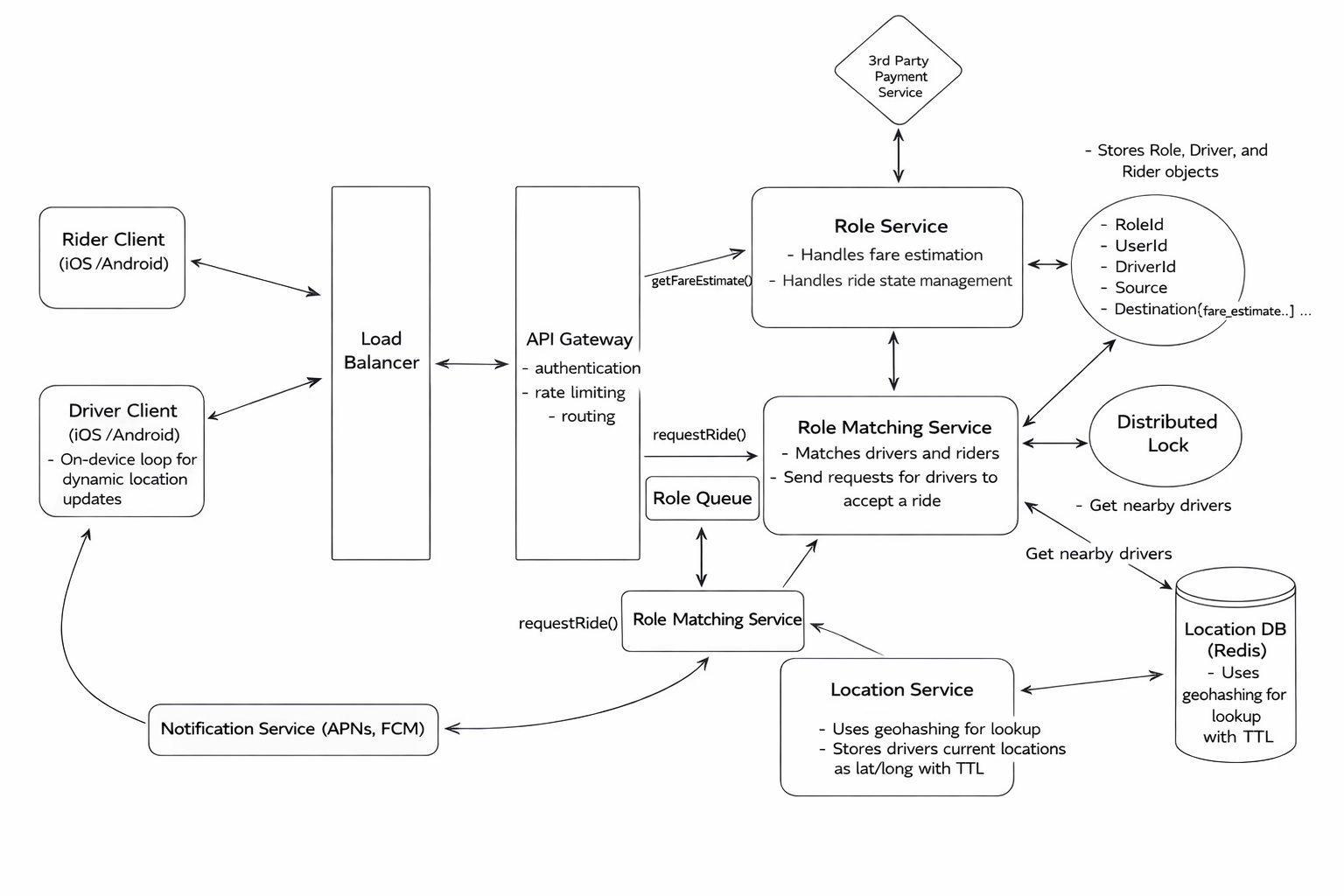
Real OpenAI system design questions often center on LLM-powered, large-scale systems like enterprise search or real-time recommendations. Strong answers integrate LLMs into robust infrastructure, balancing latency, cost, safety, and scalability.
Question 1: How to Design an LLM-Powered Enterprise Search System (Interview-Ready Guide)
Designing an LLM-powered enterprise search system came up as one of the most common system design questions during my senior SWE interviews, especially in final onsite rounds. I quickly realized why interviewers like this question so much: it forces you to show whether you can integrate large language models into a real, production-grade distributed system—rather than treating an LLM as a black-box API.
With OpenAI reporting over 800 million weekly ChatGPT users in 2025, interviewers clearly expect candidates to think at massive scale. During my interview, it wasn’t enough to say “we’ll use an LLM.” I had to reason about scalability, reliability, cost, latency, and safety—all at once—and explain how each design choice holds up under real-world load.
What helped me most was framing my answer as a series of deliberate trade-offs. Instead of jumping into architecture diagrams, I focused on why each component existed and where an LLM actually adds value. The breakdown below reflects the exact way I structured my thinking in the interview, and why these design decisions matter in an OpenAI-style system design discussion.
Step 1: Clarify the requirements.
Before designing anything, it’s critical to clarify what the system is expected to do. Strong candidates don’t jump into architecture immediately—they define the problem first.
1.1 Functional Requirements
An enterprise search system should:
Support full-text and semantic search across internal data sources (documents, emails, databases)
Accept natural language queries such as “What was our Q1 2025 revenue?”
Rank results using context and relevance
Return summaries or direct excerpts, not just raw documents
1.2 Non-Functional Requirements
Equally important are system-level constraints:
Low latency (near real-time responses)
High scalability (large corpora + high query volume)
Strong security, including role-based access control
High accuracy and precision in retrieval
Framing the problem this way signals that you’re thinking like a product-aware system designer—not just an algorithmic problem solver.
Step 2: Define a High-Level Architecture
At a high level, this system combines traditional search infrastructure with LLM-based reasoning.
2.1 Core Components
LLM (e.g. GPT) for query understanding, re-ranking, and summarization
Embedding model to convert documents and queries into vector representations
Search infrastructure
Keyword search engine (Elasticsearch / Solr)
Vector database (FAISS / Pinecone)
Document storage (SQL or NoSQL, depending on data structure)
Frontend/UI for user interaction
2.2 High-Level Flow
User submits a natural language query
Query is interpreted and embedded
Hybrid retrieval combines keyword + vector search
Results are ranked and optionally re-ranked
LLM generates a concise summary or answer
Response is returned to the user
This hybrid approach balances precision, recall, and cost efficiency.
Step 3: Drill Down into Key Components
3.1 Data Ingestion
Enterprise data typically comes from many sources. The system should:
Use connectors (APIs, file systems, databases)
Preprocess and chunk documents via ETL pipelines
Support incremental updates instead of full re-indexing
3.2 Retrieval Strategy
Vector search handles semantic similarity
Keyword search ensures exact matching and precision
Hybrid retrieval consistently outperforms either method alone
3.3 LLM Usage (Selectively)
LLMs should be used where they add the most value:
Interpreting user intent
Re-ranking top results
Generating summaries or direct answers
Using LLMs for raw retrieval is expensive and unnecessary—this distinction matters in interviews.
Step 4: Scaling, Security, and Trade-Offs
Scalability & Performance
Stateless services with horizontal scaling
Sharded document and vector stores
Caching frequent queries and results (e.g. Redis)
Security
Enforce role-based access control before retrieval
Filter unauthorized content before passing data to the LLM
Prevent sensitive data leakage at the summarization stage
Monitoring & Observability
Query latency and throughput
Retrieval accuracy and relevance
Token usage and LLM cost tracking
Key Challenges Interviewers Expect You to Address
Challenge | Why It Matters |
|---|---|
Latency vs Accuracy | LLM reasoning improves quality but adds delay |
Data Consistency | Search index and vector DB must stay in sync |
Cost | Embeddings + LLM inference scale quickly |
Final Takeaway
A strong answer to this question shows that you understand LLMs as part of a larger system, not as a standalone solution. The best designs use LLMs sparingly—where reasoning and summarization matter—while relying on robust search infrastructure for speed, scale, and reliability.
If you can explain this system clearly, you’re demonstrating exactly what interviewers look for: end-to-end thinking, practical judgment, and system-level maturity.
Question 2: Build a Real-Time Recommendation System
The second question in my openai system design interview was:
"Design a real-time recommendation system for personalized content delivery. How would you ensure low latency and high relevance?"
I started by asking about the types of content, how often recommendations should update, and what data I could use for personalization. The interviewer wanted a system that could handle millions of users and adapt quickly to new data.
I mapped out the main components:
User Data Collection: Gather user actions, preferences, and feedback in real time.
Feature Engineering: Transform raw data into features for the recommendation model.
Model Serving: Deploy models that can score and rank content instantly.
Caching: Store popular recommendations to reduce computation.
Monitoring: Track latency, accuracy, and fairness.
Safety and Compliance: Filter out unsafe or biased content.
I explained how I would use a streaming platform like Kafka for real-time data, a feature store for engineered features, and a model server with autoscaling. I suggested using Redis or Memcached for caching. For monitoring, I would set up dashboards and alerts. I also talked about adding safety filters to every recommendation.
Note: Always ask about safety, fairness, and compliance. OpenAI cares a lot about these areas.
My Approach and Thought Process
During the openai system design interview, I realized that interviewers wanted to see how I think, not just what I know. They looked for clear decision-making, especially when requirements were vague or changing. I tried to show that I could stay calm and organized, even when I didn’t have all the answers.
Here’s what I focused on:
What Interviewers Want | How I Showed It |
|---|---|
Nuanced decision-making | I explained trade-offs and considered safety and ethics. |
Clarity under ambiguity | I asked clarifying questions and summarized what I understood. |
Systems fluency | I talked about memory, network, and failure scenarios. |
Bias towards building tools | I suggested reusable tools and dashboards, not just one-off solutions. |
Simplifying complexity | I broke big problems into smaller, manageable parts. |
I learned that it’s okay to say, “Here’s what I’d do with more time,” or “If requirements change, I’d adjust this part.” That shows flexibility and real-world thinking.
If you want to stand out, focus on your thought process as much as your technical answer.
OpenAI System Design Interview Process
Topic Two: Interview Stages Overview
OpenAI’s interview process is designed to evaluate judgment, learning ability, and communication—not credentials. Each stage progressively tests how you think under ambiguity, from résumé screening to multi-hour system design interviews.
Stage 1: Application and Résumé Review
The process begins with submitting an application. According to OpenAI, the recruiting team typically reviews résumés within about one week. From a candidate’s perspective, this stage is less about listing credentials and more about clearly demonstrating impact, ownership, and problem-solving experience.
Résumés that explain what problems you worked on, how you approached them, and what outcomes you achieved align much better with OpenAI’s evaluation style than résumé keyword matching.
Stage 2: Introductory Calls
If there is a potential fit, a recruiting coordinator schedules an introductory call with a recruiter or hiring manager. While this conversation may feel informal, it serves several important purposes:
Confirming alignment between your background and the team’s needs
Understanding your motivations and long-term goals
Assessing whether you have a genuine understanding of OpenAI’s work
OpenAI recommends reviewing their blog posts and recent research updates, and in my experience, this preparation matters. The discussion often reveals whether a candidate has taken the time to understand the organization beyond surface-level interest.
Stage 3: Skills-Based Assessment
The next stage involves one or more skills-based assessments, which vary by role. These may include pair programming interviews, technical tests, or take-home projects. Some roles require multiple assessments.
What stands out in this stage is that success is not defined by speed or clever tricks. Interviewers look for well-designed solutions, thoughtful trade-offs, code quality, and clear explanations. The recruiting team provides preparation guidance in advance, and candidates are evaluated on how they reason through problems rather than whether they produce a perfect solution.
Stage 4: Final Interviews
Final interviews typically span 4–6 hours across 1–2 days, involving conversations with multiple team members. Interviews are conducted virtually by default, with an option to interview onsite.
These interviews are intentionally challenging and designed to stretch candidates beyond their comfort zones. For engineering roles, evaluation focuses on:
System design quality and scalability
Performance considerations and failure handling
Code clarity and testability
Communication, collaboration, and feedback handling
Throughout this stage, interviewers are not just assessing technical skill, but how you think, explain, and collaborate in high-stakes environments.
Decision and Feedback
Candidates typically hear back within one week of the final interviews. At this stage, recruiters may request references. The decision process reflects the same principles as the interviews themselves: clarity, consistency, and signal-based evaluation.
Final Reflection
After completing the process, it became clear that OpenAI interviews are not about producing flawless answers. They are about demonstrating judgment, learning ability, communication, and alignment with OpenAI’s mission and values. Understanding this hiring philosophy early can fundamentally change how you prepare—and how you perform—throughout the interview process.
Topic Three: What to Expect and How to Prepare for the OpenAI System Design Interview
OpenAI system design interviews prioritize structured thinking over memorized architectures. Interviewers assess how you clarify scope, reason about tokens and cost, handle safety concerns, and design systems that fail gracefully under real-world constraints.
From my experience, the OpenAI system design interview is not a test of how many architectures you’ve memorized. It’s an evaluation of how you think when requirements are ambiguous, constraints are real, and decisions have long-term consequences. Understanding what to expect fundamentally changes how you should prepare.
What to Expect in the Interview
First, expect the interview to be context-driven, not template-driven. Interviewers rarely want you to jump straight into drawing boxes. Instead, they observe how you clarify scope, user experience, and constraints before proposing solutions. Questions are often open-ended by design, forcing you to define the problem before solving it.
Second, expect the discussion to be token- and cost-aware, not just request-based. OpenAI systems are shaped by tokens, latency, and GPU constraints. Interviewers look for candidates who naturally reason in terms of throughput, generation speed, batching trade-offs, and inference cost—rather than treating LLMs as abstract black boxes.
Third, expect a strong emphasis on safety, privacy, and responsibility. Prompt moderation, output filtering, data retention, and abuse prevention are not “nice-to-have” topics. They are core system requirements. If your design ignores safety or logging controls, it will feel incomplete no matter how elegant the architecture is.
Finally, expect interviewers to probe failure modes and judgment calls. They are less interested in perfect designs and more interested in how your system behaves under stress: timeouts, GPU saturation, prompt overload, or malicious inputs. How you design guardrails often matters more than how you optimize the happy path.
Area | What You Must Be Able to Do | Interview Signal |
|---|---|---|
Problem Framing | Clarify user type, scope, latency, safety before designing | Thinks like a product + infra owner |
Requirement Scoping | Define what’s in / out of scope early | Avoids over-engineering |
Estimation & Math | Convert users → requests → tokens → cost | Production realism |
Model Awareness | Explain GPT-4 vs GPT-3.5 trade-offs | Cost & quality judgment |
Architecture Design | Walk through end-to-end request flow clearly | Systems clarity |
Prompt Lifecycle | Explain preprocessing, routing, moderation | LLM-native thinking |
Safety & Moderation | Treat safety as default, not optional | Mission alignment |
Caching Strategy | Use exact + semantic caching appropriately | Token efficiency |
Routing Logic | Route by tier, complexity, or load | Scalability maturity |
Privacy & Logging | Optional logging, redaction, retention | Responsible AI |
Observability | Monitor tokens, latency, abuse signals | Trust & reliability |
Failure Handling | Design fallbacks and graceful degradation | Senior-level judgment |
Topic Four: Preparation Tips and Strategies
Effective preparation focuses on mental frameworks, not volume. Practice clarifying requirements, doing fast token math, designing clean end-to-end flows, and explaining trade-offs aloud—this mirrors how OpenAI evaluates candidates.
Recommended Study Resources
I found that the right resources made a huge difference in my prep. I started with OpenAI’s official blog and documentation. These gave me a sense of the company’s priorities and the tech stack they use. I also watched YouTube talks by OpenAI engineers. These videos helped me see how they think about system design and AI safety.
I read “Designing Data-Intensive Applications” by Martin Kleppmann. This book gave me a strong foundation in distributed systems. I also checked out “ML System Design” by ByteByteGo for machine learning system patterns. For hands-on practice, I built small projects using OpenAI’s APIs. This helped me understand real-world challenges.
Tip: Don’t just read—try building something. Even a simple chatbot or data pipeline can teach you a lot.
Effective Practice Routines
I broke my practice into small, focused sessions. I spent time using OpenAI’s products to see how they work from a user’s view. I built UI components and handled async data instead of just solving algorithm puzzles. I reviewed system design basics, like distributed systems and real-time apps. I also read about prompt engineering and model limits to get comfortable with AI concepts.
Here’s a table that shows the routines I followed:
Practice Routine | Description |
|---|---|
Start with OpenAI’s Products | Use OpenAI tools to learn their engineering approach. |
Practice Practical Coding | Build UI components and handle async data. |
Study System Design Fundamentals | Review distributed systems and real-time application basics. |
Get Comfortable with AI Concepts | Read about prompt engineering and model limitations. |
Timeline and Expectations | Spend 2-3 weeks, focusing on different topics each week. |
I set a schedule and stuck to it. Consistency helped me build confidence.
Structuring Your System Design Answers
When I answered system design questions, I used a simple framework. I started by clarifying the use case. I asked about the main goal and who would use the system. Next, I estimated the scale—how many users, how much data, and what kind of performance was needed. I then sketched a modular architecture, breaking the system into clear parts.
I always discussed trade-offs. I explained why I picked one approach over another. I looked for bottlenecks and talked about how to fix them. I made sure to mention security and how the system could scale in the future.
Here’s a quick reference table:
Framework Component | Description |
|---|---|
Clarifying Use Cases | Understand what the system needs to do. |
Estimating Scale | Figure out expected load and performance. |
Sketching Modular Architecture | Draw a high-level design with main components. |
Discussing Trade-offs | Weigh pros and cons of each choice. |
Identifying Bottlenecks | Spot and address performance issues. |
Security Considerations | Keep the system safe from threats. |
Scaling Strategies | Plan for future growth and demand. |
If you follow this structure, you’ll sound organized and thoughtful. Interviewers notice that.
Topic Five: Final Takeaway
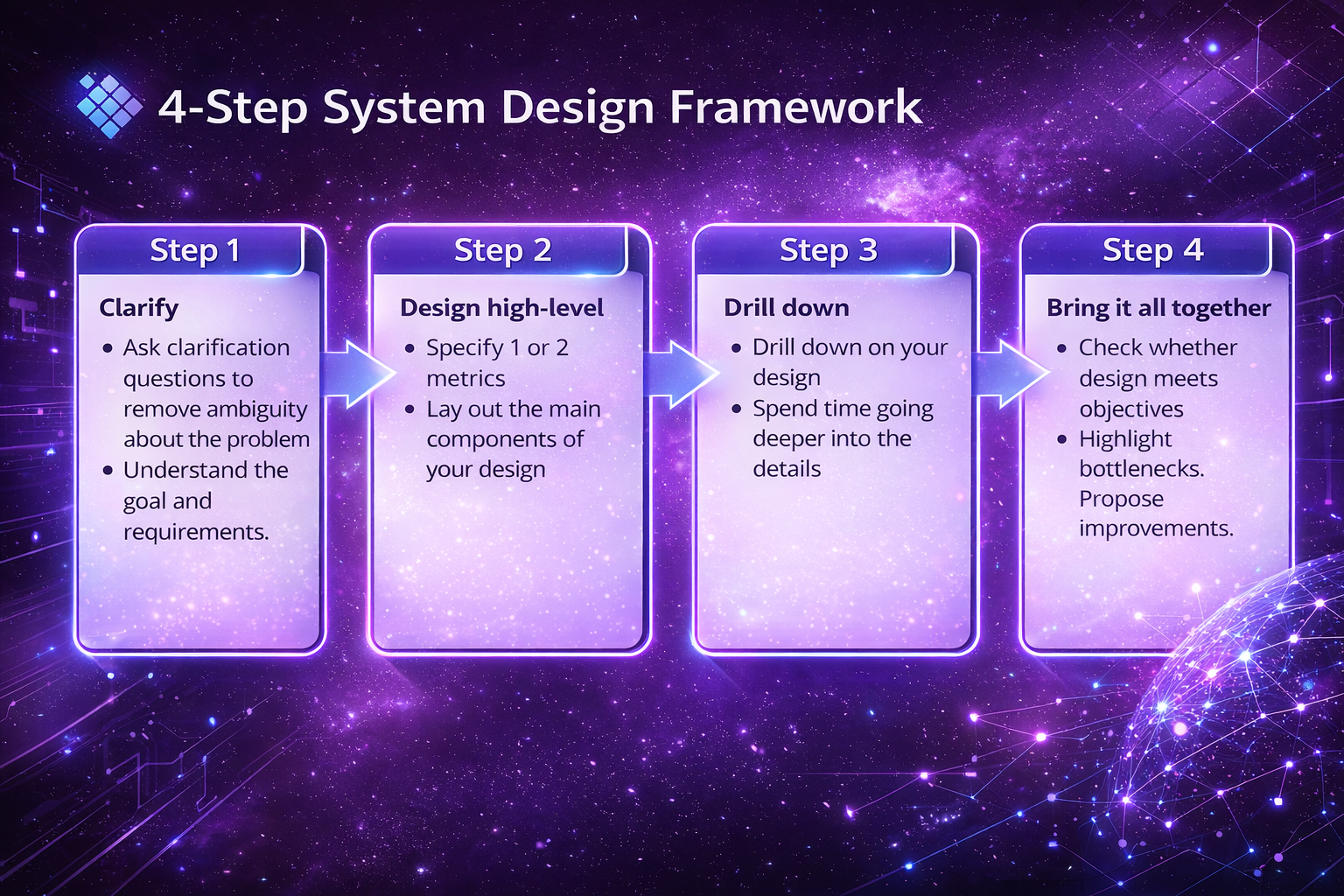
In OpenAI system design interviews, structure is the answer. Interviewers grade how you reason, communicate, and make decisions under uncertainty—not how complex your diagram looks.
After going through dozens of system design interviews—and especially OpenAI-style ones—I realized something critical: interviewers aren’t grading your diagram, they’re grading your thinking.
This 4-step framework works because it mirrors how real engineers reason under uncertainty: clarify before building, design before optimizing, drill down before polishing, and only then step back to evaluate trade-offs. If you sound structured, you are structured in the interviewer’s eyes.
Personally, what helped me most was using Linkjob AI during preparation and live interviews. It quietly kept track of earlier requirements, reminded me of missing constraints, and helped me stay aligned with this exact framework—especially when pressure made it easy to jump ahead or lose structure. I didn’t need perfect answers; I needed clear judgment, delivered calmly.
If you remember one thing, let it be this:
In system design interviews, structure is not a bonus—it is the answer.
Once you internalize that, even the hardest open-ended questions start to feel manageable.
FAQ
Why does the OpenAI system design interview often include LLM-powered enterprise search questions?
Because this type of question tests end-to-end system judgment, not API familiarity.
Enterprise search forces candidates to reason about real production constraints: large datasets, high QPS, strict access control, low latency, and cost-aware LLM usage. Adding an LLM on top introduces safety, scalability, and reliability trade-offs that mirror real OpenAI systems.
Interviewers use this question to evaluate whether you understand how LLMs fit into distributed infrastructure, rather than treating them as standalone solutions.
In an OpenAI system design interview, should the LLM handle retrieval or only reasoning and summarization?
Only reasoning and summarization.
Strong OpenAI-style designs rely on:
Keyword search for precision
Vector search for semantic recall
LLMs are selectively for intent interpretation, re-ranking, and summarization
During the interview process, I used LinkjobAI to review my answers and identified instances where I overrelied on large language models. This reinforced a critical interview takeaway: while powerful, large language models come at a high cost—they should not replace core search infrastructure. LinkJobAI not only outputs correct answers but also enhances your own responses, making them more insightful and comprehensive.
How do you explain hybrid search clearly in an OpenAI interview?
In one or two sentences.
Hybrid search combines keyword search (precision) with vector search (semantic intent). Together, they deliver higher recall and better ranking quality than either approach alone, while remaining scalable.
In OpenAI interviews, clarity beats depth. A concise explanation that ties hybrid search to accuracy, cost, and scale is far more effective than diving into implementation details.
What are the biggest scalability challenges OpenAI interviewers expect you to address in LLM-powered search systems?
Three issues consistently matter:
Token growth and inference cost
Index consistency between search and vector stores
GPU saturation during traffic spikes
When practicing, LinkjobAI helped me consistently connect these challenges back to concrete design choices—like sharding, caching layers, and tiered model routing—so my answers stayed grounded and production-aware instead of theoretical.
What is the most common mistake candidates make in OpenAI system design interviews?
Making the LLM the center of the system.
In reality, OpenAI-style systems are built on:
Search and retrieval infrastructure
Data ingestion pipelines
Access control and privacy boundaries
Observability and monitoring
LLMs enhance these systems—they do not replace them. Candidates who recognize this consistently deliver clearer, more credible system design answers.
See Also
Navigating the OpenAI Interview Process: My 2025 Journey
Insights from My 2025 Perplexity AI Interview Experience
Successfully Acing My 2025 Palantir New Grad Interview
Unveiling My 2025 Roblox SWE Interview Process and Queries
Preparing for My 2025 Generative AI Interview: The True Story

© Copyright 2026 Linkjob.ai - All Rights Reserved.