How I Passed Snowflake Software Engineer Interview 2026


I just got my Snowflake offer, and I wanted to share a few thoughts from the interview process while it’s still fresh. Overall, Snowflake’s software interviews didn’t feel like pure algorithm screens, unlike Anthropic software engineer interview. A lot of the questions looked fairly simple at first, but the follow-ups often pushed the discussion toward distributed systems and data infrastructure pretty quickly.
Recommending an undetectable AI interview assistant. During an interview, it can capture the interviewer's questions and output answers in real-time. I got my offer by using it.
Key Takeaways
The overall Snowflake interview process is fairly standard, but the technical flavor is different.
The coding questions are not always classic LeetCode-style problems.
The hardest part is often not the question itself, but the depth of the follow-up.
For both technical and behavioral rounds, ownership matters a lot.
Snowflake Software Engineer Interview Stages
The overall process felt pretty standard: an OA first, then a technical phone screen, and then the virtual onsite loop. Nothing especially unusual in terms of structure. The pace also moved fairly quickly. If things were going smoothly, it seemed possible to get through the whole process in around two weeks.
Online Assessment
The OA wasn’t especially tricky from a pure problem-solving standpoint. It mostly centered around three areas: SQL, basic Python, and some light statistics or data-processing logic. The overall style felt pretty consistent with Snowflake’s product focus — less algorithm-heavy, more grounded in data workflows. If you’ve spent time building data pipelines or doing practical data analysis, that background probably helps.
One recent Snowflake OA I went through felt on the harder side compared with a lot of big-tech OAs.
It was a 120-minute round with 3 questions, and all three felt comfortably above the “easy template” level. What made it challenging wasn’t that the problems were unusually weird — it was that they all demanded real modeling. You needed a complete approach, careful edge-case handling, and at least some attention to performance. If you slowed down on one question, it was pretty easy to start feeling the time pressure.
The three problems were:
String Patterns
Paint the Ceiling
Task Scheduling

1. String Patterns
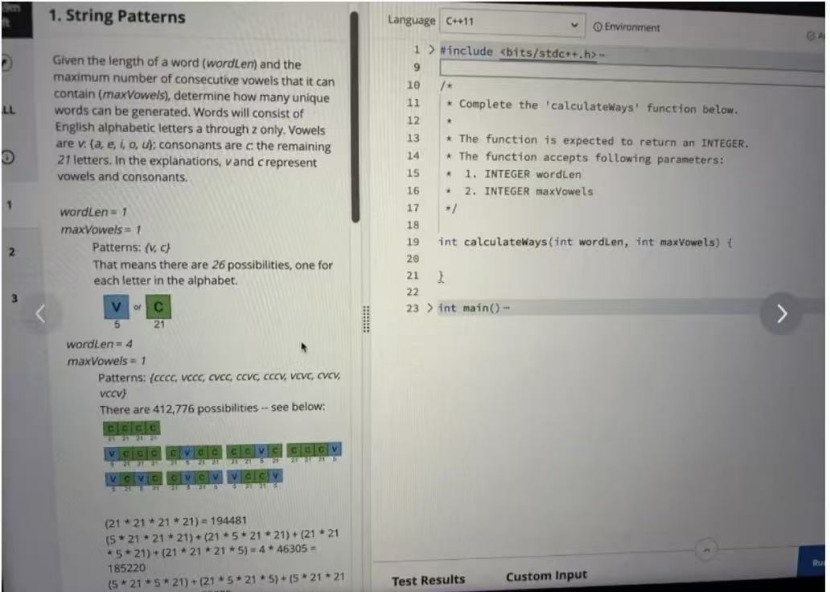
This problem gives you a word length, wordLen, and a limit, maxVowels, for how many vowels can appear consecutively. The task is to count how many valid words can be formed using lowercase English letters.
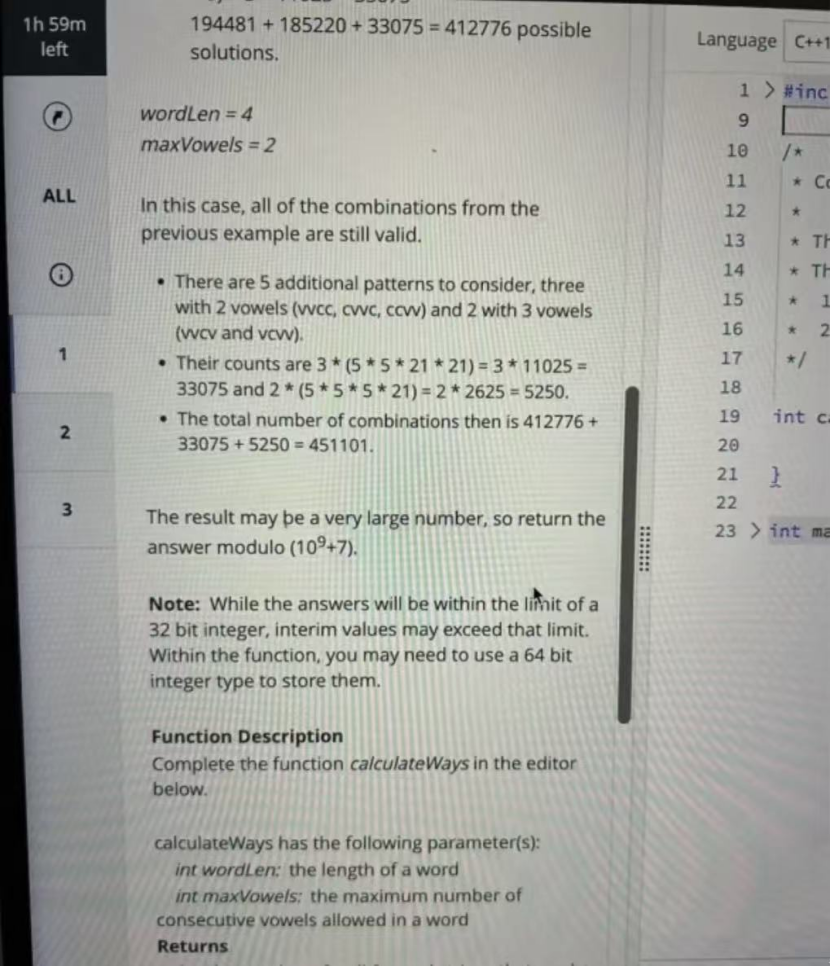
The vowels are {a, e, i, o, u}, and the other 21 letters are treated as consonants. A word is considered valid as long as no run of consecutive vowels is longer than maxVowels. The final answer is returned modulo 10^9 + 7.
How I thought about it
For this one, a dynamic programming approach felt the most natural.
I defined dp[i][j] as the number of valid strings of length i that end with exactly j consecutive vowels.
From there, the transitions were pretty straightforward:
Add a consonant:
dp[i][0] = (sum of all states from length i - 1) * 21
Since any previous valid string can take a consonant next, the consecutive vowel count resets to0.Add a vowel:
dp[i][j] = dp[i - 1][j - 1] * 5forj <= maxVowels
If I place a vowel, I’m extending the current run of consecutive vowels by one.
The base case is dp[0][0] = 1, and then you just build it up until wordLen. At the end, sum over all valid j values and take everything modulo 10^9 + 7.
2. Paint the Ceiling
Problem summary
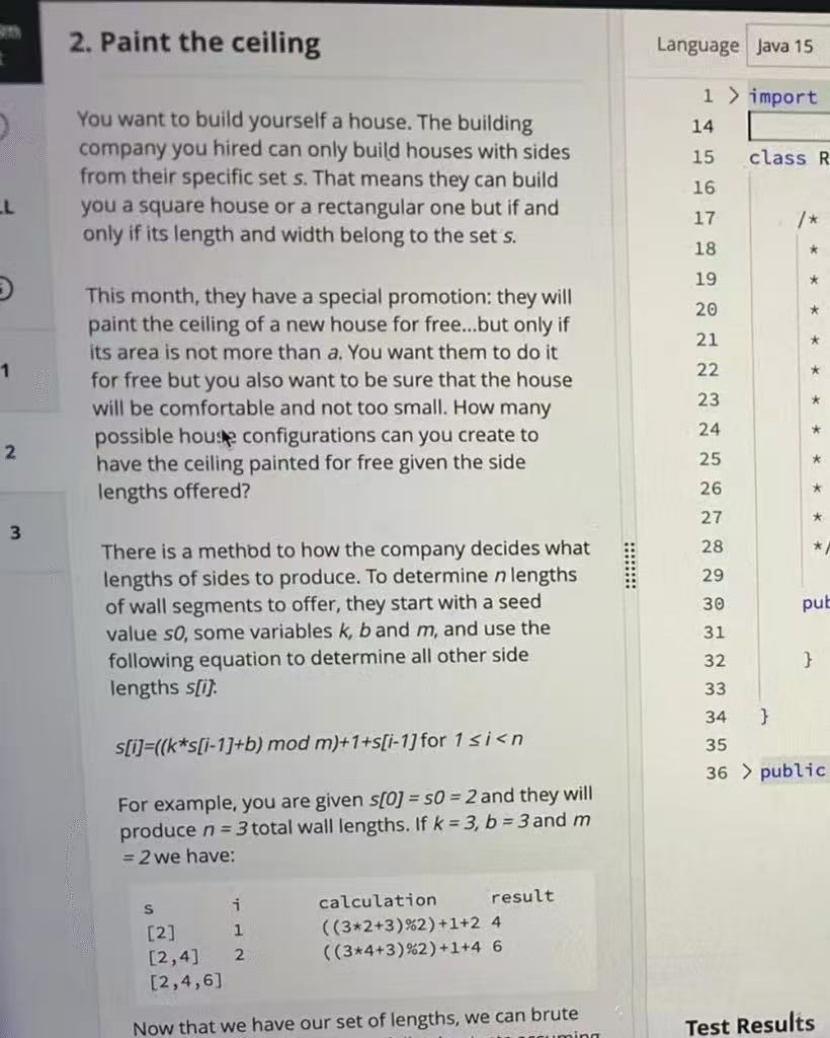
A construction company generates a sequence of side lengths s using a recurrence formula. From this sequence, we need to choose two side lengths (the same value can be chosen twice, which would correspond to a square) as the length and width of a house.
The only constraint is that the product of the two side lengths — in other words, the ceiling area — cannot exceed a given value a.
The final task is to count how many valid choices there are.
How I thought about it
The first step is to generate the side-length sequence using the formula provided in the problem:
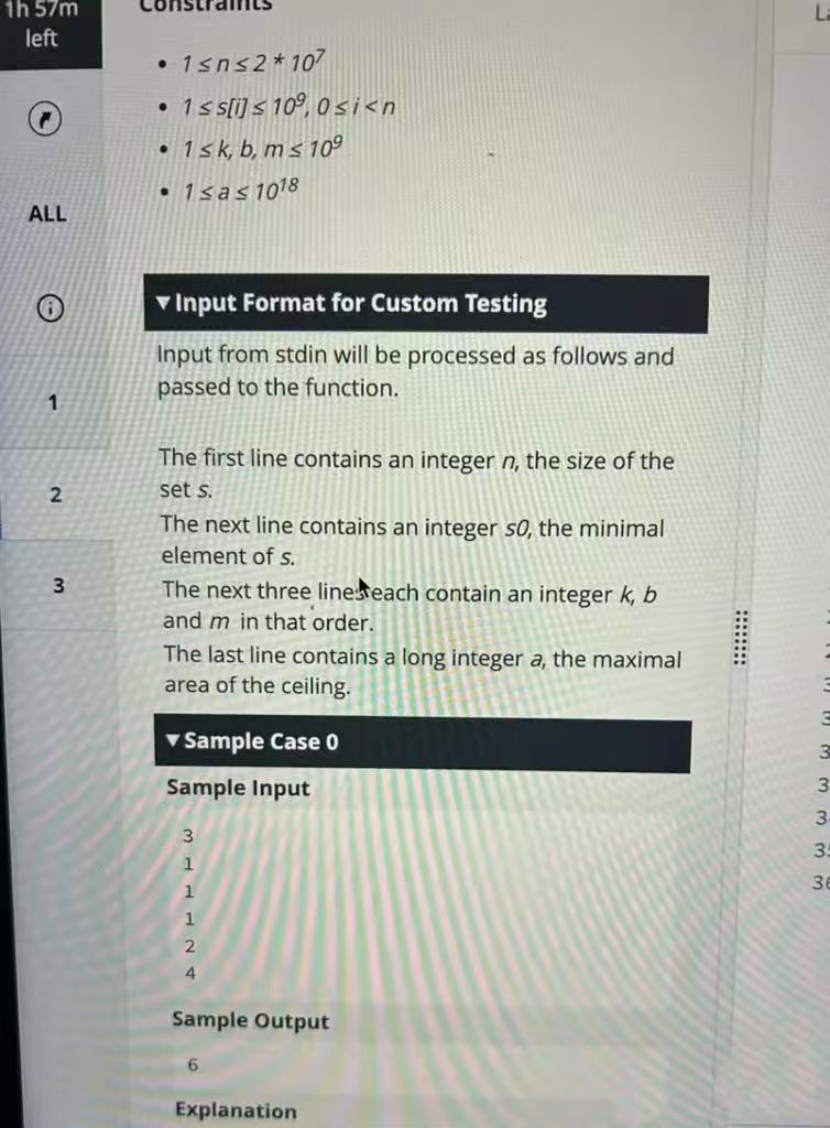
s[i] = ((k * s[i - 1] + b) mod m) + 1 + s[i - 1]
Starting from s[0], we generate a total of n side lengths.
To avoid repeated counting, we can deduplicate the sequence and sort it in ascending order.
After that, the problem becomes counting all rectangle combinations in the set that satisfy:
x <= y and x * y <= a
One way to do this is to enumerate each smaller side x, then look to the right for all values of y that still satisfy the area constraint, and count all valid pairs.
A two-pointer approach also works. One pointer, left, starts from the smallest value, and the other pointer, right, starts from the largest.
If
S[left] * S[right] <= a, then for the currentleft, every element fromlefttorightis valid, so we add those combinations to the answer and moveleftforward.Otherwise, we move
rightbackward.
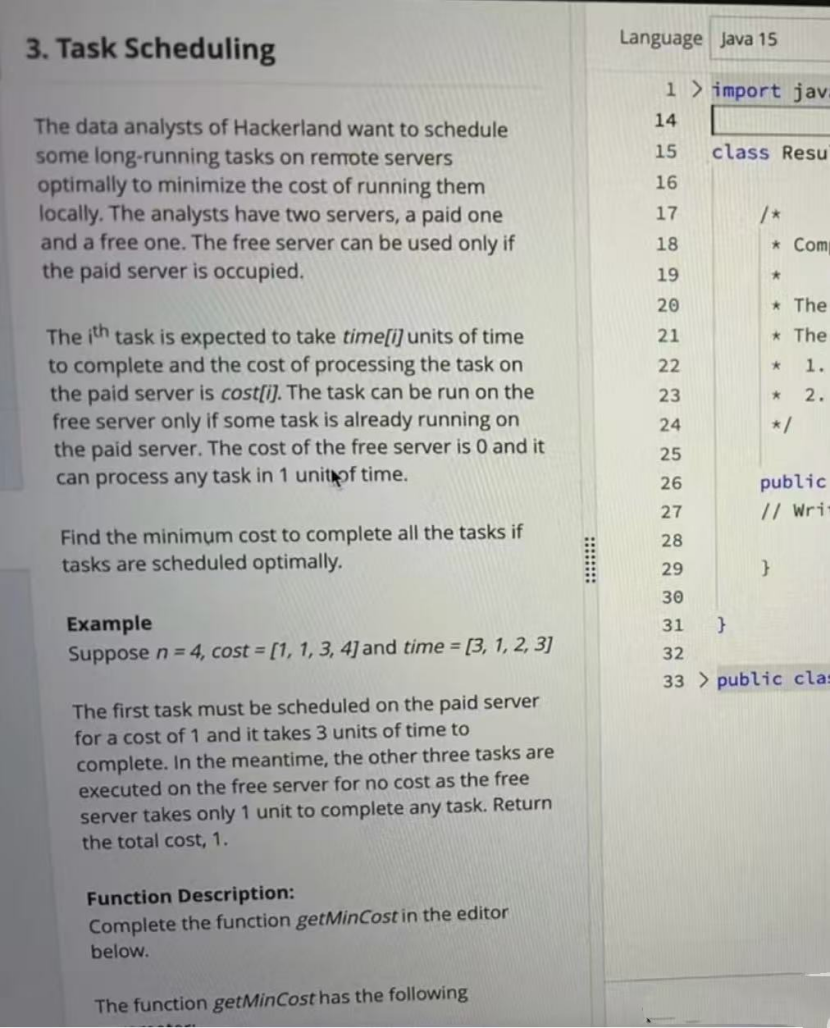
3. Task Scheduling
Problem summary
There are two servers:
a paid server, where task
itakestime[i]time units and costscost[i]a free server, where each task takes
1time unit and costs0, but it is only available while the paid server is busy
The goal is to find the minimum total cost needed to finish all tasks.
How I thought about it
The key to this problem is understanding how the free server works.
As long as the paid server is running, the free server can process tasks in parallel, and each free task only takes 1 unit of time.
So if we assign a task to the paid server, that task not only finishes itself, but also creates time[i] free-task slots. In other words, choosing that task on the paid server effectively “covers” time[i] + 1 tasks.
That turns the problem into:
choose some tasks to run on the paid server so that all tasks are covered
(total coverage >= n), while keeping the total cost as small as possible.
At that point, it becomes essentially a 0/1 knapsack problem, and we can use dynamic programming to compute the minimum cost.
Technical Phone Screen
By the time I got to the phone screen, I could already feel Snowflake’s technical taste a lot more clearly.
A lot of people assume the coding round will just be the usual LeetCode-style interview, but in practice, they seem to like problems that are a bit closer to simulating system behavior.
One example that comes up a lot is a browser-tab style question: design a data structure to simulate browser tab behavior, such as opening a new tab, closing a tab, and going back to the previous page.
Writing the code is only the first step. What the interviewer really seems to care about is how you organize state, how you guarantee the complexity of each operation, and whether performance starts to break down when the number of tabs becomes very large.
1. Coding
① Web Crawler
The core idea is based on BFS, which is the typical approach for this kind of problem.
More specifically, you use a Queue to store the URLs waiting to be crawled, and a HashSet or Bloom Filter to record visited URLs and avoid infinite loops.
Complexity: O(N) time, O(N) space, where N is the number of webpages.
② Parentheses Matching
The key idea is to use a Stack.
When you see a left parenthesis, you push it onto the stack. When you see a right parenthesis, you check whether the top of the stack matches it.
Follow-up:
For multiple types of brackets such as (), [], and {}, you can build a Map to store the matching relationship — for example, ) maps to (, and ] maps to [. The overall logic stays the same.
Complexity: O(N) time, O(N) space.
③ Service Startup
This problem is essentially about service dependency ordering, which corresponds to LeetCode 210.
The standard solution is Kahn’s algorithm. The main idea is to maintain an in-degree table and an adjacency list, put all nodes with in-degree 0 into a Queue first, and then process the remaining nodes step by step.
Follow-up:
If the output needs to be grouped by level, you can use standard BFS level-order traversal. In each round, you process all nodes currently in the queue together. Those nodes belong to the same level and represent services that can be started in parallel.
Follow-up:
Multi-core acceleration is an important extension of this problem. When there are multiple nodes with in-degree 0 in the queue, you can use a ThreadPool to execute them in parallel. After a task finishes, you update the in-degree of its dependent nodes using atomic operations. If a node’s in-degree drops to 0, it can then be added to the task queue.
Complexity: O(V + E) time, O(V + E) space.
2. System Design
One part I found pretty interesting was the system design round.
Snowflake’s design questions usually don’t feel like the standard “design a generic web service” type of interview. They tend to be much closer to data-platform problems — things like a quota service, a data-processing pipeline, or a resource scheduling system.
What seemed to matter a lot was whether you could start from requirement breakdown instead of jumping straight into boxes-and-arrows architecture. In that sense, the conversation felt pretty aligned with how real system design discussions usually go. If you naturally brought up ideas like fault tolerance, horizontal scaling, or eventual consistency, you were probably already moving in the right direction.
Example: Designing a DAG Cache
Use case
When a query view generates a DAG, design a caching mechanism to improve access efficiency.
High-level idea
Key generation: For each sub-query in the DAG, compute a hash of its logical plan and use that result as the cache key.
Storage design: Since query results can be large, store metadata in Redis, and store the actual data in S3 or another distributed file system.
Main challenge
The hard part is cache-update consistency — once the underlying data changes, how do you keep the cache in sync?
Possible approaches
Active invalidation: Build a reverse index between data sources and cache keys. When an underlying table is updated, recursively invalidate all cached intermediate results that depend on that table.
Versioning: Add version tags to the data and include version information in the cache key. After a data update, a new cache key is generated, while old cache entries expire naturally through TTL.
Virtual Onsite
By the time I got to the onsite, the loop usually split into a few rounds with pretty different styles.
One of them was the tech talk, which is basically a project discussion. A lot of people treat it like a simple walkthrough, but it felt much more important than that. In practice, most of the later deep-dive discussion seemed to branch out from whatever you presented here.
The more mature way to handle it, at least from what I saw, was to structure the project around three layers:
the problem background
the technical choices
the trade-offs
That framing worked especially well because Snowflake’s engineering culture seems to care a lot about architecture decisions. If you can explain why you chose a particular approach — not just what you built — that tends to land much better.
Why I Chose Snowflake Software Engineer
I applied to Snowflake because it felt like the kind of place where the engineering bar was high in a useful way.
What stood out to me was how often people described the learning curve as steep, especially early on. I kept seeing the same pattern: engineers joined, got pushed hard, and grew fast. That was appealing to me. I wasn’t looking for a role where I could stay comfortable for a year. I wanted an environment that would force me to get better.
I was also drawn to the ownership culture. From everything I had seen and heard, Snowflake seemed like a place where engineers were expected to think beyond just their immediate tasks and build a real understanding of the systems they were working on. That matched what I was looking for.
The mentorship side also mattered. A lot of companies say they invest in onboarding, but Snowflake came up often in conversations about strong technical ramp-up and access to senior engineers. My impression was that the expectations were high, but there was real support behind them.
At the same time, it didn’t sound like an easy place to work, and I actually mean that in a positive way. The pace seemed fast, and the problems seemed real. That was a big part of the appeal.
Resume and Cover Letter
Before the interviews started, I mainly tried to make my application materials clear and relevant.
What I focused on
Put the strongest technical signals near the top
Highlighted backend, data, and infrastructure-related work
Wrote project bullets around problem, action, result
Used numbers when they showed real impact
Cover letter
Kept it short
Used it to explain why Snowflake and why this role
Avoided repeating the resume
Tip:The strongest resume bullets usually show what changed, not just what you worked on.
Recruiter and Hiring Manager Calls
The early calls felt pretty relaxed, but they were still important.
Recruiter call
Mostly about background, role fit, and why I was interested in Snowflake
Felt like a basic alignment check
Hiring manager call
More specific than the recruiter screen
Focused more on past projects and how my experience matched the team
What I tried to do
Asked a few real questions about the team’s work and expectations
Used the calls to understand whether the role was actually a good fit
Tip: For these calls, being clear on why you want this company and this role matters more than sounding overly polished.
Application and Initial Steps of Snowflake Software Engineer Interview
Preparation for the Snowflake Software Engineer Interview
Study Resources
For prep, I found it more useful to focus on resources that matched Snowflake’s technical flavor rather than generic interview advice.
One guide that helped was Snowflake System Design Interview: A Complete Guide. It covered ideas that seemed especially relevant to Snowflake, like multi-cluster shared data, storage and compute separation, and query optimization. It gave me a clearer sense of how Snowflake’s architecture differs from a more typical backend system.
I also used LeetCode for coding practice and spent some time reading about Snowflake’s newer features to keep my understanding current.
Practice Strategies
What worked best for me was a mix of technical and behavioral prep.
On the technical side, I reviewed core data structures and algorithms regularly, especially dynamic programming and graphs. I also looked into security and data governance, since those seemed relevant enough to be worth knowing.
On the behavioral side, I spent time reflecting on past projects and thinking through examples around problem-solving, ownership, and adaptability.
One thing that helped a lot was practicing how to explain my thinking clearly while solving problems.
Tip: Clear communication matters a lot. Interviewers usually care about how you think, not just whether you get the final answer.
Mock Interviews
Mock interviews helped more than I expected.
I did a few with friends and used them mainly to get comfortable with the pressure, pacing, and back-and-forth of a real interview. They also helped me notice where my explanations were still unclear.
The main areas I focused on were:
data-centric problem solving
clean and efficient solutions
edge case handling
complexity analysis
explaining ideas clearly, including in SQL-related contexts
That practice made the real interviews feel much less unfamiliar.
Challenges and Solutions about Snowflake Software Engineer Interview
Difficult Interview Questions
A few Snowflake questions definitely made me pause.
What stood out was that the interviewers seemed to care less about getting an instant answer and more about how I thought through the problem. A lot of the topics were familiar on paper — stack vs. queue, binary search, cycle detection in a linked list, dynamic programming, or optimizing a slow SQL query — but the real challenge was explaining them clearly and going one layer deeper when prompted.
What helped most was keeping my thinking structured: break the problem down, talk through the approach, and ask clarifying questions when needed.
Tip: In these rounds, clear reasoning matters at least as much as the final answer.
Managing Stress and Time
Prep felt much more manageable once I broke it into phases instead of treating it like one huge task.
I spent some time refreshing fundamentals, then focused on coding, SQL, system design, and mock interviews in a more structured way. Shorter, focused study blocks worked better for me than long sessions, and having a simple plan made it easier to stay consistent.
Staying Motivated
There were definitely days when prep felt repetitive.
What helped was focusing on smaller wins — solving a hard problem, doing better in a mock interview, or explaining something more clearly than before. Staying in touch with friends or other people preparing also made the process feel less isolating.
More than anything, motivation came from seeing gradual progress, even when it felt small.
Lessons and Advice about Snowflake Software Engineer Interview
Tips for Future Candidates
A few things helped me more than others during the process.
I practiced coding pretty consistently, mostly to stay sharp rather than to memorize patterns.
I spent some time understanding Snowflake’s culture, especially the emphasis on ownership, collaboration, and clear communication.
For system design, I tried to go beyond architecture diagrams and talk about trade-offs, especially around cost, security, and scalability.
I also prepared behavioral stories in advance, with a focus on problem-solving, adaptability, and working across teams.
When it made sense, I tied my past work to concrete results using numbers instead of vague descriptions.
Tip: Snowflake interviews seemed to reward clear thinking and good communication at least as much as raw technical knowledge.
Common Mistakes
A few patterns felt easy to get wrong.
focusing too much on coding while underpreparing for behavioral or communication-heavy rounds
giving technically correct answers without connecting them to real impact
ignoring cost or security considerations in system design discussions
treating the interview like a pure algorithm screen when the company clearly cares about systems thinking
Avoiding those mistakes probably matters more than trying to sound overly polished.
Final Thoughts
Looking back, the process pushed me in useful ways.
It made me better at explaining technical decisions, thinking more carefully about trade-offs, and staying structured under pressure. More than anything, it reminded me that interview prep is usually less about one big breakthrough and more about steady improvement over time.
If you’re preparing now, I’d probably keep the advice simple: stay consistent, stay curious, and don’t make the mistake of preparing only for the coding part.
FAQ related to Snowflake Software Engineer Interview
How did I prepare for system design?
I broke big topics into smaller pieces, read about Snowflake’s architecture, and practiced sketching simple systems. Saying my ideas out loud helped, and feedback from friends made it easier to see where my thinking was still fuzzy.
What did I do when I got stuck in coding?
I tried not to freeze. I kept talking through the problem, solved the part I understood first, and asked for a hint if I really needed one. Staying structured usually helped more than forcing a perfect answer.
How important were behavioral interviews?
Pretty important. Snowflake seemed to care a lot about ownership, collaboration, and handling ambiguity. I used real examples from past projects and tried to make that connection clear.
What resources helped most?
The main ones were:
LeetCode
Snowflake docs
system design guides
mock interviews with friends
Tip: It’s usually better to choose resources based on your weak spots.
Can you apply without cloud experience?
I think so. What seemed to matter more was whether you could learn quickly, connect your past work to relevant problems, and show genuine interest in the space.
See Also
Navigating My Oracle Senior Software Engineer Interview in 2026
Successfully Acing My Palantir New Grad SWE Interview 2025
Key ES6 Interview Questions That Led To My Hiring in 2025
Real Questions And Answers From My Technical Support Engineer Interview
Insights From My Databricks New Grad Interview Experience in 2026

© Copyright 2026 Linkjob.ai - All Rights Reserved.