I Passed 2025 Box HackerRank Assessment Here Are the Questions


The Box SWE HackerRank OA consists of three questions with a 120-minute time limit. Overall, the three problems in this OA covered Array/String Manipulation, Validation and Calculation, and a problem involving Simulation and Data Structures. I would rate their difficulty as follows: Box Froyo (Problem 1): Easy Counterfeit Currency (Problem 2): Medium Retention Policy Collision (Problem 3): Hard
I genuinely appreciate how much Linkjob.ai has helped me throughout the process, which is why I’m sharing all of my OA details here. Having an invisible AI interview helper running in the background really takes away a lot of stress.
This article is part of the HackerRank series. If you're interested in other articles in this series, feel free to read: Microsoft HackerRank test, JP Morgan HackerRank test, Stripe HackerRank online assessment.
Box HackerRank Assessment Questions
Question 1: Box Froyo

My Understanding:
This problem is about finding the shortest path in a circular array. Imagine a frozen yogurt machine where the flavors are arranged in an array that is connected end-to-end (circular). My task is to move from the starting position startIndex to the location of the target flavor target, and find the minimum number of steps required, whether moving left or right.
My Solution Strategy:
Since the arrangement is circular, there are only two paths from startIndex to targetIndex: clockwise and counter-clockwise.
Find the Target Index: First, I iterate through the flavors array to find the index targetIndex of the target flavor.
Calculate the Clockwise Distance (d_right):
If targetIndex >= startIndex, the clockwise distance is targetIndex - startIndex.
If targetIndex < startIndex, since it's circular, we wrap around the end of the array. The distance is (n - startIndex) + targetIndex, where n is the array length.
Calculate the Counter-Clockwise Distance (d_left):
The counter-clockwise distance is simply the total length n minus the clockwise distance: d_left = n - d_right.
Find the Minimum: The final result is min(d_right, d_left).
This problem is essentially finding the shortest distance between two points on a circle, which is very straightforward.

Question 2: Counterfeit Currency
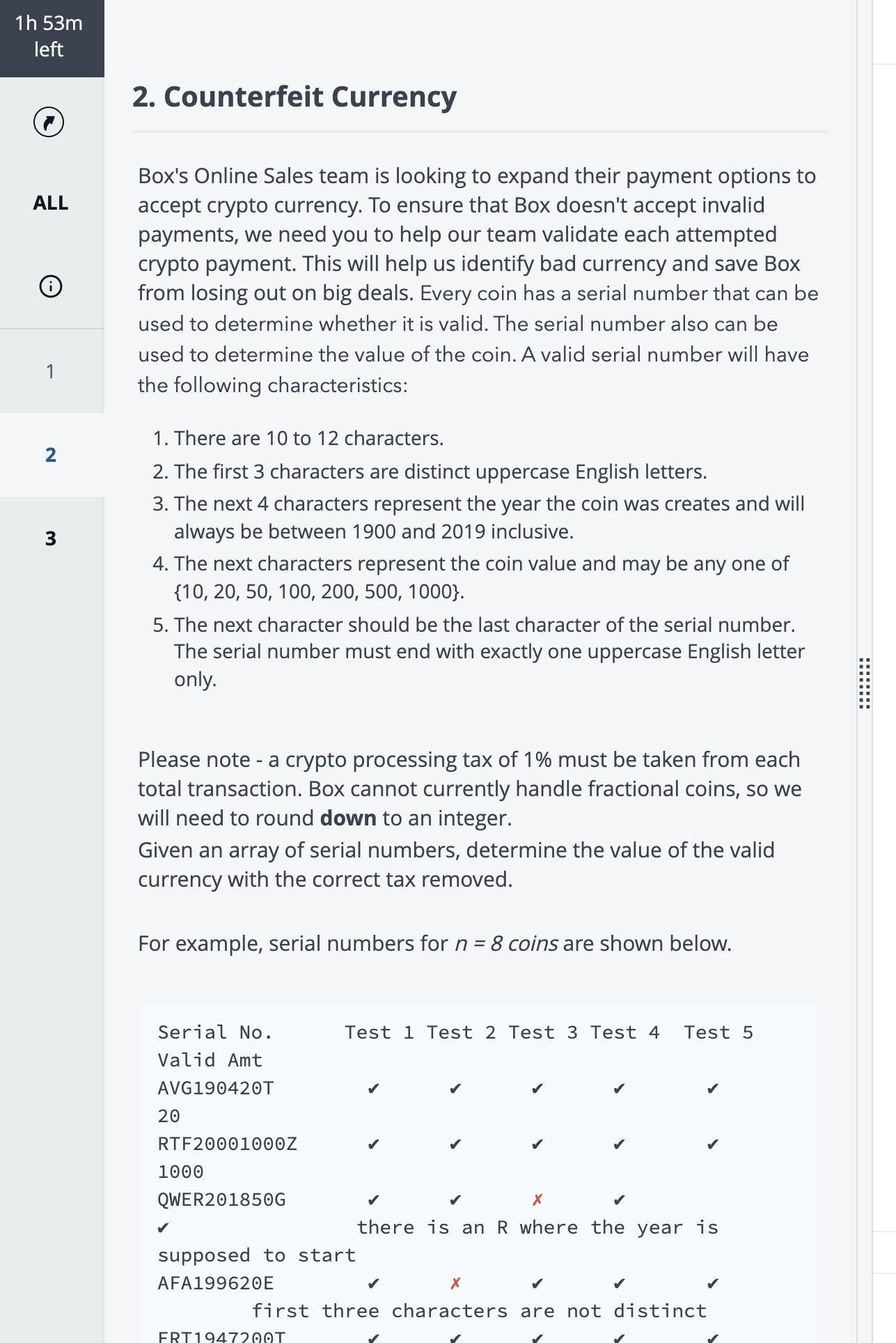
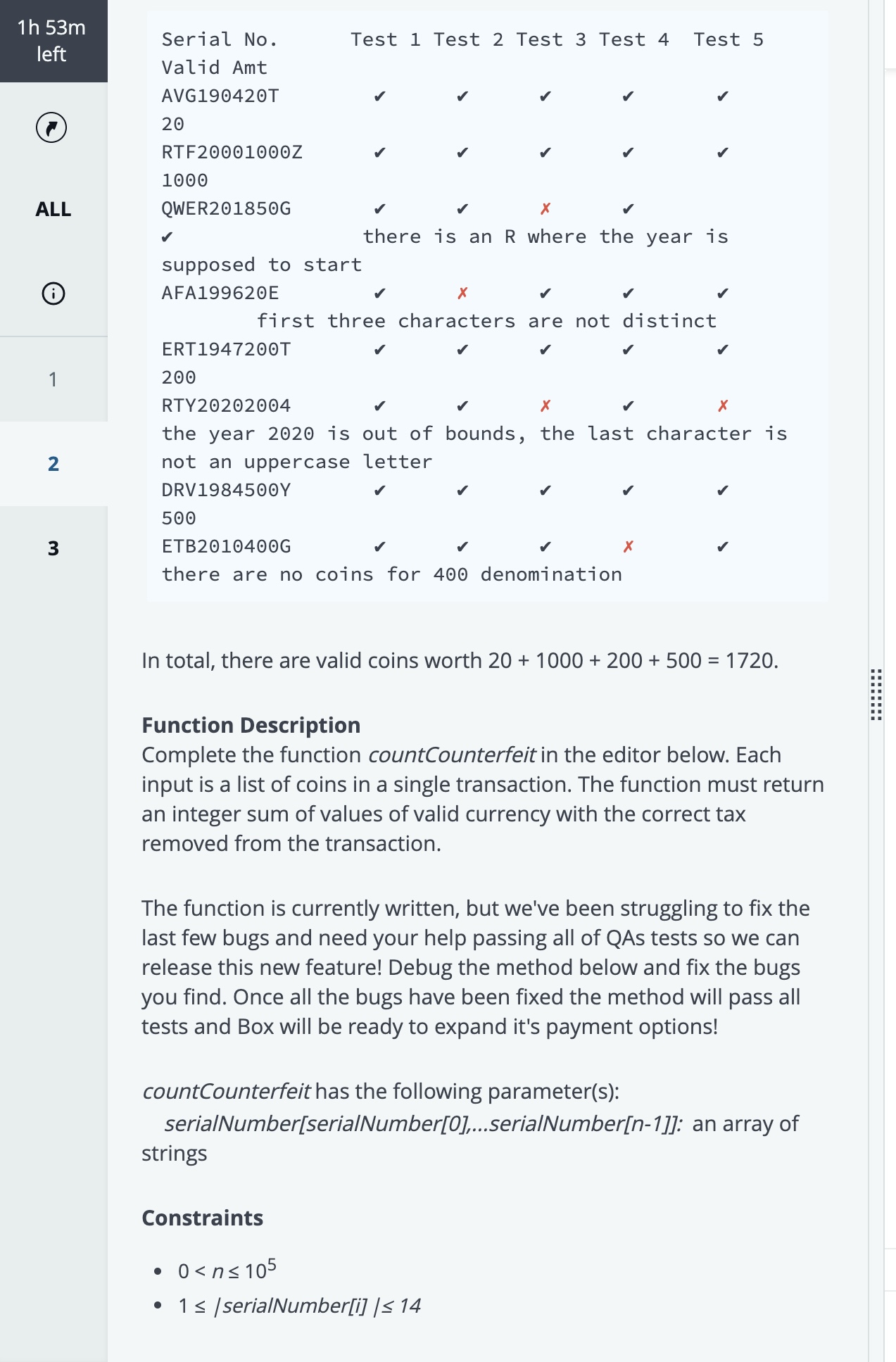
My Understanding:
This problem is a typical string validation and processing challenge. I need to implement a function that takes a list of coin serial numbers and checks if each serial number is valid based on five strict rules. Only valid serial numbers can contribute their face value to the total, and the final sum must be subjected to a 1% tax removal and rounded down to an integer.
My Solution Strategy:
I used a step-by-step validation and accumulation approach:
Main Loop: Iterate through every string in the input serialNumber array.
Five-Step Validation Function (isValid): I implemented a boolean function for each serial number to check all rules. A serial number is valid only if all rules pass.
Rule 1 (Length): Check if the length is between 10 and 12, inclusive.
Rule 2 (First Three): Check if the first three characters are all distinct uppercase English letters. I used a Set or hash map to quickly check for duplicate characters among these three.
Rule 3 (Year): Check if characters 4-7 (4 characters) are digits, and the represented year is between 1900 and 2019, inclusive.
Rule 4 (Value): Check if the substring from the 8th character to the second-to-last character (S[7] to S[len-2]) is one of the valid denominations ({10, 20, 50, 100, 200, 500, 1000}).
Rule 5 (Last Character): Check if the last character is exactly one uppercase English letter.
Value Extraction and Accumulation: If a serial number passes all checks, I extract its face value (the number mentioned in Rule 4) and add it to the running sum totalValue.
Final Calculation: After processing all serial numbers, perform the tax calculation and rounding:
valueAfterTax = totalValue * (1 - 0.01)
Finally, return floor(valueAfterTax) (round down to the nearest integer).
The key to this problem is meticulously implementing every validation detail, especially character types, ranges, and substring extraction.
HackerRank's detection system is extremely strict, but as outlined in the article “HackerRank How to Cheat,” modern AI interview software like Linkjob has already developed the capability to bypass the platform's detection mechanisms. I highly recommend this article, as it shares numerous useful tips.
I have to say, Linkjob AI was incredibly useful. I wasn’t detected at any point during the interview, and the complete code answers it provided were really helpful. I just had to click a button and let the AI solve the problems for me. Plus, it was completely invisible to the interviewer, as shown in the image above.
Question 3: Retention Policy Collision
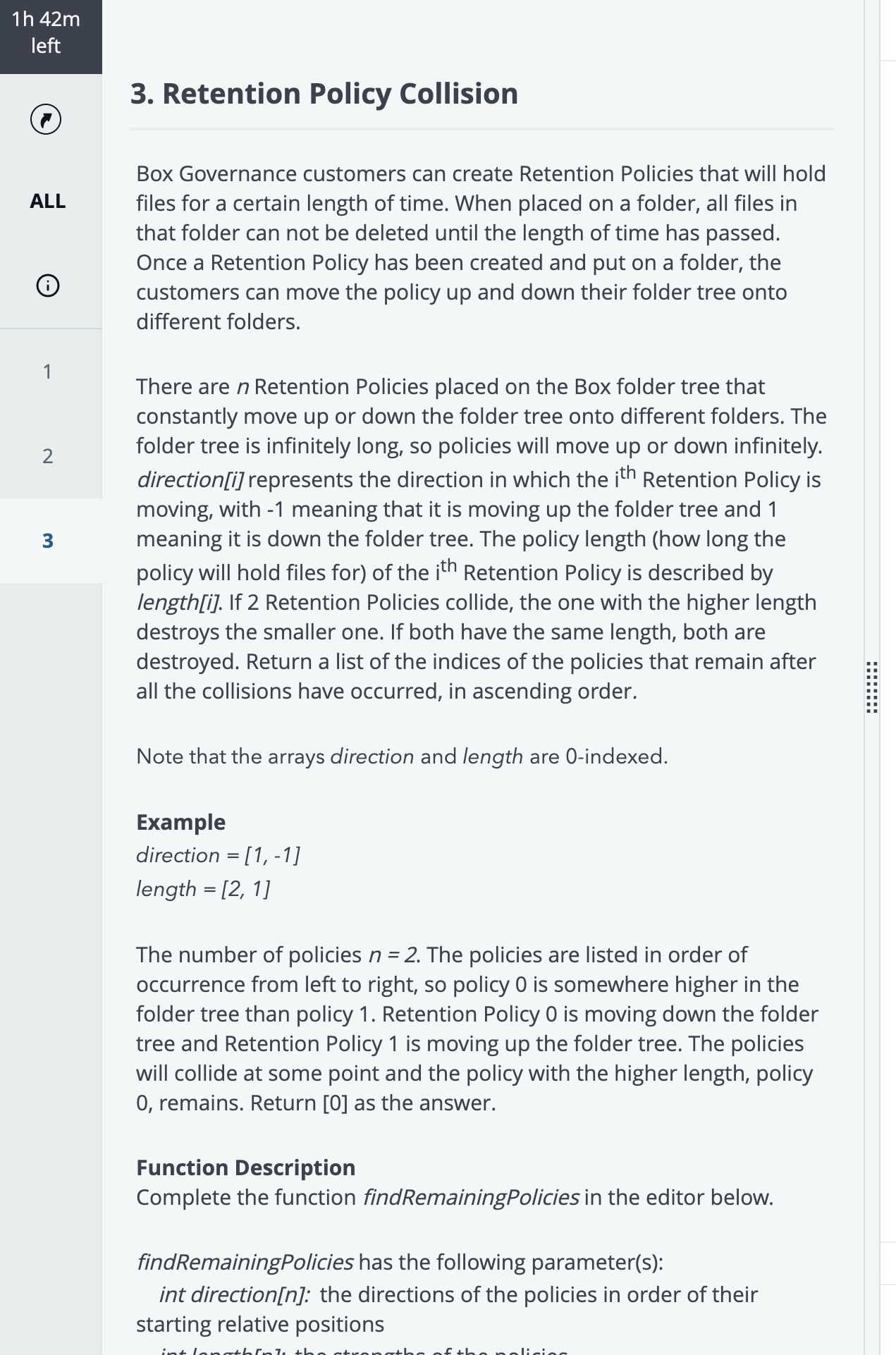
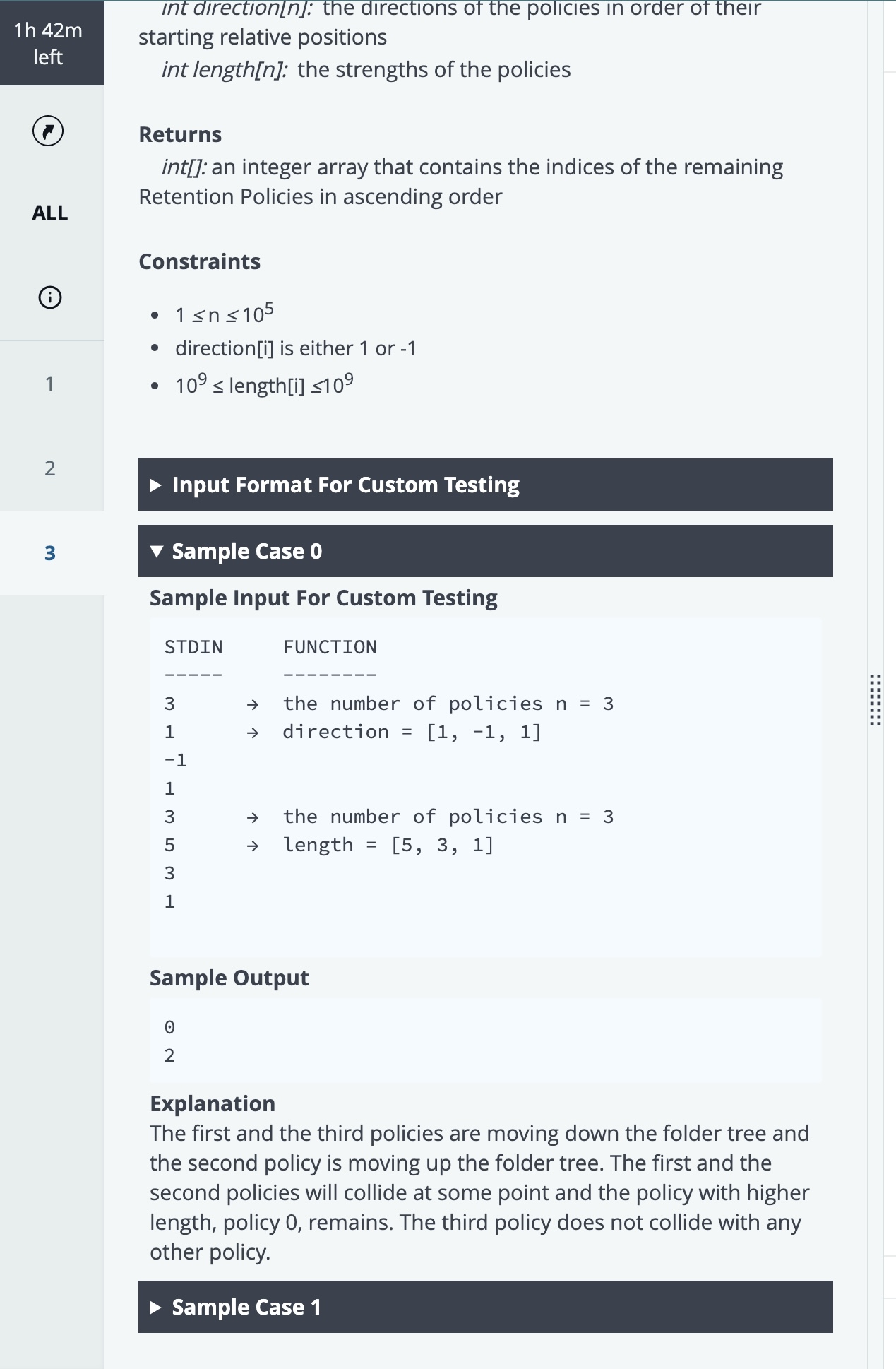
My Understanding:
This is a challenging problem that simulates a physical collision process, but in a linear space (imagine a 1D coordinate axis, the "folder tree"). I need to process n retention policies, each with a direction (direction) and a strength (length). The policies move at different speeds and directions. When they meet (collide), they follow these rules:
Collision Mechanism: The policy with the greater strength (length) wins and remains.
Tie Mechanism: If the strengths of the two policies are equal, both are destroyed.
My task is to return the original indices of the policies that ultimately survive, sorted in ascending order.
My Solution Strategy:
This is a classic collision problem that can be solved using a Stack or Queue, as collisions only occur between adjacent policies moving towards each other. I chose to use a Stack to simulate the process:
Policy Abstraction: I treat each policy as an object/tuple containing three pieces of information: (index, direction, length).
Stack Operation: Iterate through all policies. For the current policy P_current = (i, d_i, l_i), I push it onto the stack. However, before pushing, I need to check if an immediate collision will occur.
Collision Detection and Handling: A collision can only happen between the top element of the stack P_top and P_current, and they must be moving towards each other.
P_top must be moving right (direction = 1).
P_current must be moving left (direction = -1).
As long as the stack is not empty and P_top is moving right (1) and P_current is moving left (-1), enter the collision loop:
l_i > l_top: P_current wins. P_top is destroyed (popped from the stack). Continue the loop; P_current will collide with the new stack top.
l_i < l_top: P_top wins. P_current is destroyed (not pushed onto the stack). Break the collision loop, proceed to the next original policy.
l_i = l_top: Both are destroyed. P_top is destroyed (popped from the stack). P_current is also destroyed. Break the collision loop, proceed to the next original policy.
Final Result: After iterating through all policies, the elements remaining in the stack are the survivors. I extract the original indices index of these policies, sort them, and return the result.
This method cleverly uses the LIFO (Last-In, First-Out) property of the stack to ensure we always handle the most recent possible collision. This was the most challenging of the three problems, requiring a clear understanding of data structures and the simulation process.
Box HackerRank Test Overview
The assessment was designed to evaluate fundamental programming skills, algorithmic thinking, and the ability to handle practical data processing and simulation challenges.
Core Technical Focus Areas
The three problems collectively tested the following core competencies, presented here as specific knowledge points:
Problem | Primary Focus Area | Key Knowledge Points Tested |
1. Box Froyo | Array/Geometric Manipulation | Circular Arrays: Understanding index wrapping and boundary conditions (0 to n-1). |
Shortest Path Calculation: Determining minimum distance on a circular/cyclic structure. | ||
2. Counterfeit Currency | String Processing & Validation | String Parsing/Substrings: Extracting specific data segments (year, value, letters) based on fixed indices/lengths. |
Data Validation: Implementing multiple, layered rules (length, uniqueness, character type, numeric range lookup). | ||
Data Type Conversion: Converting string segments to integers for comparison and calculation. | ||
Financial Calculation: Accurate percentage calculation (1% tax removal) and floor function for rounding (floor (x)). | ||
3. Retention Policy Collision | Algorithms & Data Structures (Simulation) | Stack Implementation: Using a Stack (LIFO structure) to efficiently manage and process sequential, adjacent interactions (collisions). |
Stateful Simulation: Modeling a dynamic process (moving policies) and applying complex rules (collision logic, win/loss/tie conditions) iteratively. | ||
Abstract Modeling: Mapping a physical process (particles colliding) onto a computational data structure (elements interacting on a stack). |
Additional Relevant Points
Beyond the specific technical skills, the assessment also strongly emphasized the following soft skills and engineering practices:
Attention to Detail: Success required meticulous adherence to all constraints, such as case sensitivity, exact range boundaries, and unique character requirements. Small errors in validation logic led to test case failures.
Edge Case Handling: Candidates needed to ensure solutions handled edge scenarios correctly, such as startIndex = targetIndex or equal strengths causing mutual destruction.
Time Complexity Awareness: Although the constraints (N <= 10^5) for Problem 3 suggested an efficient solution (O(N) or O(N log N)), the stack-based simulation naturally provides a highly efficient O(N) solution because each policy is pushed onto the stack at most once and popped at most once.
This OA provided a comprehensive test of basic programming dexterity and the ability to apply the right data structure to solve a complex, simulated scenario efficiently.
Preparation Strategy for Box HackerRank OA
I structure my preparation to cover foundational computer science principles and efficient problem-solving techniques. My goal is to be ready for any standard category of algorithm problem.
Fortify Foundational Data Structures
Since the assessment format is unknown, mastering the fundamental building blocks of algorithms is my first priority. These structures are the tools I use to achieve efficiency.
Arrays, Strings, and Matrices: These form the basis of most problems. I practiced problems involving efficient searching, sorting, string manipulation, and two-pointer techniques to ensure I could solve linear data problems quickly.
Stacks and Queues: These are essential for any problem involving sequences, histories, or dependencies. Being able to spot a LIFO (Stack) or FIFO (Queue) pattern is a huge time-saver.
Hash Maps: This is the single most important structure for turning potentially O(N^2) solutions into efficient O(N) solutions. I focused on using Hash Maps for counting frequencies, looking up constraints, and storing pre-computed results.
Master Essential Algorithm Categories
I divided my algorithm practice into the most commonly tested categories to ensure comprehensive coverage.
Search and Sorting: I ensured I was comfortable with Quick Sort, Merge Sort, and especially Binary Search, which is a key technique for optimizing search time from linear to logarithmic (O(log N)).
Greedy Algorithms: Many assessment problems test your ability to make the locally optimal choice hoping it leads to a globally optimal solution. I practiced recognizing when a problem can be simplified using a greedy approach.
Graph/Tree Traversal (Conceptual): Even if a problem doesn't look like a formal graph, many systems can be modeled as one. I reviewed Breadth-First Search (BFS) and Depth-First Search (DFS) for navigating complex relationships and structures.
Emphasize Code Quality and Assessment Readiness
Technical proficiency is only half the battle; the other half is performing under pressure and delivering clean, reliable code.
Focus on Time Complexity (O(N)): I mentally calculate the Big O of my proposed solution before writing the first line of code. For typical N constraints (up to 10^5), the solution must usually be O(N) or O(N log N). If my initial thought is O(N^2), I force myself to rethink using a Hash Map or a two-pointer technique.
Write Clean, Testable Functions: During practice, I always structured my code logically using helper functions. This modular approach makes the main logic easier to read and, critically, much faster to debug during the timed assessment.
Develop a Debugging Checklist: I established a systematic way to check for common pitfalls before submitting:
Index Bounds: Did I check i=0 and i=N-1?
Integer Overflow: Are any of my numbers going to exceed 2^31? (Important for constraints up to 10^9)
Off-by-One Errors: Did I use < or <= correctly?
Edge Cases: Does my code handle empty inputs, single-element inputs, or inputs where elements are all the same?
By preparing across these three dimensions (Foundations, Algorithm Categories, and Assessment Readiness) I ensured I had a robust toolkit to tackle whatever unique challenges the Box HackerRank OA presented.
Resource Selection
Choosing the right resources made a huge difference for me. I wanted platforms that offered real coding challenges, mock tests, and feedback. Here’s a quick comparison of the top platforms I used:
Platform | Features |
|---|---|
HackerRank | Coding challenges, skill certifications |
Codility | Coding assessments, technical interviews |
LeetCode | Top interview questions, explore sections |
I spent most of my time on HackerRank. It had a wide range of problems and was beginner-friendly. I also liked that it offered certifications to show off my skills. LeetCode and Codility helped me practice different question types and get used to the test format.
When picking resources, I followed these steps:
I assessed my current skills with a diagnostic test.
I practiced daily on HackerRank and LeetCode.
FAQ
How long is the Box HackerRank OA?
The assessment provides a total time limit 120 minutes to complete all three coding problems. Time management is crucial as the difficulty ramps up significantly with the third question.
Do I need to solve all three problems to pass?
While scoring high is always the goal, full passing usually requires passing all test cases. Passing 2.5 problems (full pass on Easy/Medium, high score on Hard) generally puts you in a strong position. Focus on 100 percent correctness for the first two to secure your foundation.
See Also
2026 Nvidia HackerRank Test: Questions I Got and How I Passed
How I Cracked 2026 Citadel HackerRank Assesment Questions
My IBM 2026 HackerRank Assessment: Real Questions & Insights
My 2026 MathWorks HackerRank Assessment Questions & Solutions
Questions I Encountered in 2026 Goldman Sachs HackerRank Test

© Copyright 2025 Linkjob.ai - All Rights Reserved.