2025 Jefferies HackerRank: My Real Experience and Questions


My HackerRank assessment for Jefferies consisted of 6 questions in total: 4 multiple-choice questions and 2 coding problems. The time limit was 60 minutes, and the test had to be completed within 48 hours of receiving the invitation. Below, I’ll share the two coding problems I encountered along with my solution approach.
I am really grateful for the tool Linkjob.ai, and that's also why I'm sharing my OA interview experience and coding questions here. Having an undetectable AI interview assistant during the interview is indeed very convenient.
This article is part of the HackerRank series. If you're interested in other articles in this series, feel free to read: Microsoft HackerRank test, JP Morgan HackerRank test, Stripe HackerRank online assessment.
Jefferies HackerRank Questions
When I took the two Jefferies HackerRank OAs, the difficulty of the questions was basically one easy and one medium. The first question, “Arranging Coins,” was a relatively simple math problem. The second, “Application Analytics,” was a medium-level system design and data structure problem. It was exactly the typical OA pattern: one basic question plus one comprehensive question.
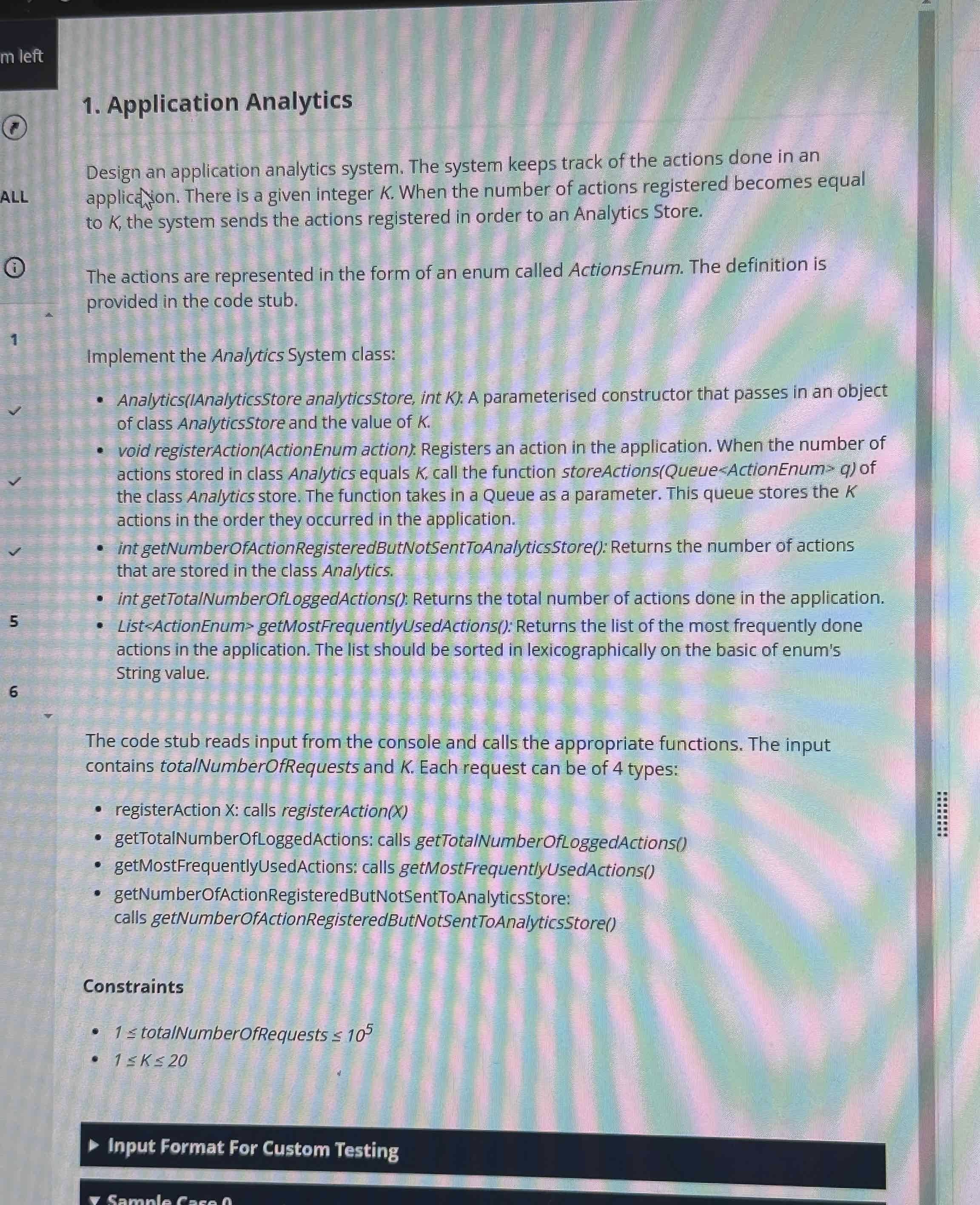
Question 1: Application Analytics
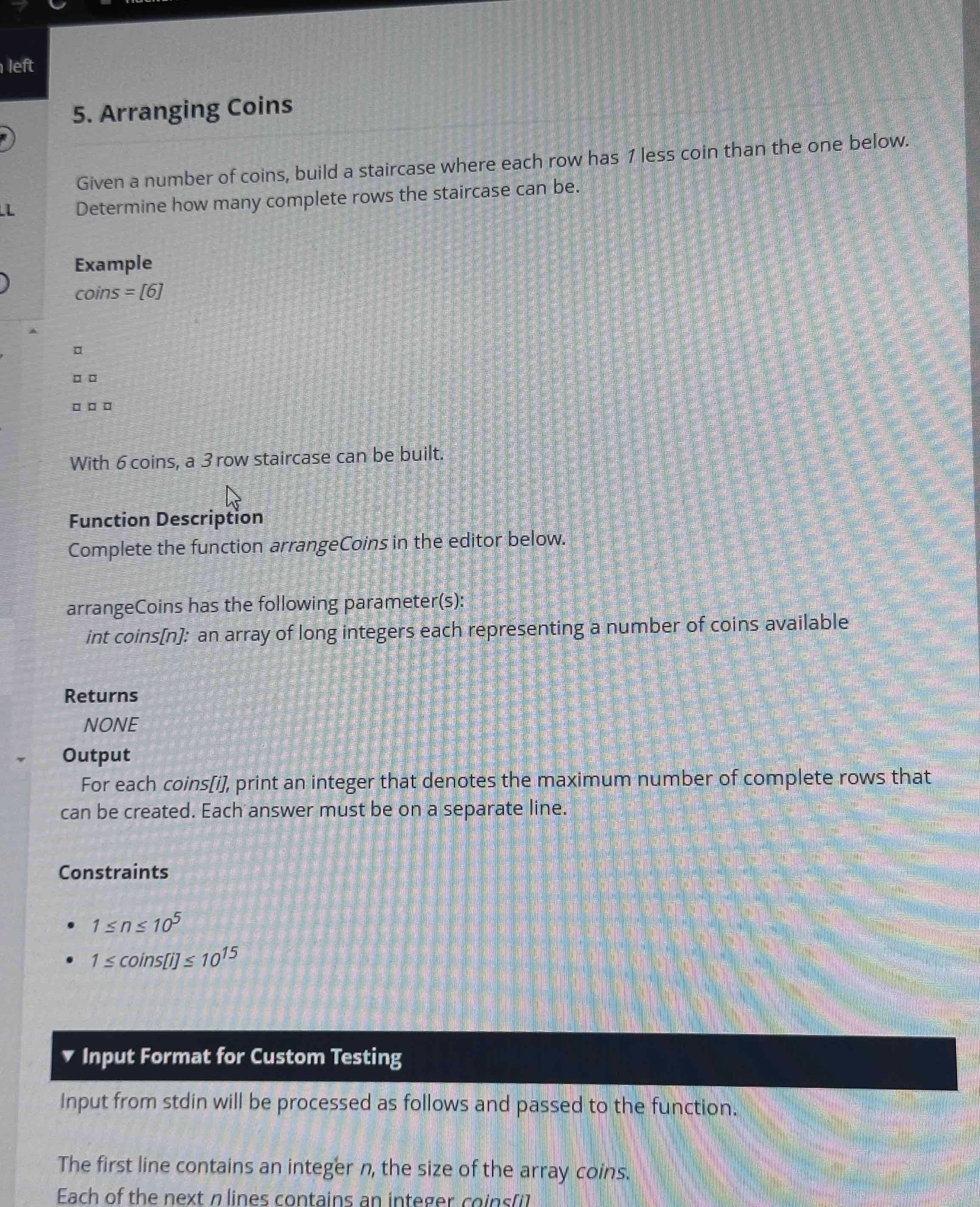
For this question, my initial reaction was that it was just a math problem. The task was to arrange coins in stair-like rows: the first row has 1 coin, the second row 2 coins, and so on, and we were asked how many complete rows could be formed given a certain number of coins.
My understanding was that the problem boiled down to finding the largest k such that 1 + 2 + … + k ≤ n. For example, if n = 6, 1 + 2 + 3 = 6, so k = 3.
I approached it in two steps:
First, I considered a brute-force approach. But if n is very large (e.g., 10¹⁵), looping through k would be too slow, so a formula was needed.
I derived the formula using the arithmetic series sum: k(k + 1)/2 ≤ n, which translates to solving the quadratic inequality k² + k - 2n ≤ 0. The largest integer k can be calculated with the formula k = floor((√(8n + 1) - 1)/2).
To avoid floating-point precision issues, I added a verification step: after calculating k, I checked whether k(k + 1)/2 or (k + 1)(k + 2)/2 satisfied the condition, ensuring no mistakes.
Finally, when handling array input, I just looped through each coin count and output the corresponding k. This question had no hidden traps; the formula alone was enough to solve it instantly.
Linkjob AI worked great and I got through my interview without a hitch. It’s also undetectable, I used it and didn't trigger any HackerRank detection.
If you're concerned about AI interview assistants evading detection on platforms like HackerRank, you can read HackerRank's guidelines on how to use AI copilots during interviews.
Question 2: Arranging Coins
The second question took me about five minutes to read. It was a system-design type programming question that required implementing multiple methods of a class, testing the comprehensive use of data structures.
My understanding was that it simulated a behavior analytics system. The core requirement was to send behaviors to storage once K actions were accumulated, while maintaining total actions, pending actions, and high-frequency actions.
I broke the requirements down and maintained them using different data structures:
For “send actions after K accumulations,” I used a queue to store pending actions. Each time registerAction was called, the action was added to the queue. When the queue length reached K, storeActions was called to send the queue, and the queue was then cleared (or replaced with a new one).
Total actions: I maintained a global variable total_actions, incremented it with each registerAction, and returned it in getTotal.
Pending actions: This was simply the current queue length, returned as queue.size().
High-frequency actions: I used a hash map (e.g., Python dict) to count the occurrences of each ActionEnum. Every time registerAction was called, the corresponding count was incremented.
To find the most frequent actions, I identified the maximum count, collected all ActionEnums with that count, sorted them by their string representation, and returned the sorted list.
The pitfalls I encountered were: clearing the queue after sending actions without resetting the hash map counts (since high-frequency actions tracked all actions), and ensuring sorting was by Enum string values, not the Enum order. Since the request volume could reach 10⁵, each method needed O(1) or O(m log m) time complexity (with m being the number of enums, relatively small) to avoid timeouts.

Jefferies Hackerrank Question Types
Basic Rank Assignment and Order Verification
This is the most fundamental question type, focusing on assigning ranks according to rules and verifying whether the ranking logic holds.
Typical format: Given a dataset such as product satisfaction scores or stock returns, assign ranks based on rules such as descending or ascending order, and handle ties with either shared ranking (1, 2, 2, 4) or continuous ranking (1, 2, 2, 3). Then determine whether the rank relationship between two samples is correct, for example, whether sample A’s rank is strictly less than sample B’s.
Key point: Do not overthink definitions. Remember how ranks are calculated in the case of ties, as this is the most common pitfall in the OA.
Rank Correlation Analysis
A high-frequency topic that tests whether the rankings of two variables are associated. The goal is to judge correlation direction or strength rather than compute the exact correlation coefficient.
Typical format: Given two sets of rank data, for example, user preference ranks for products and product sales ranks, determine using the Jeffreys Hacker test whether the two are positively correlated, negatively correlated, or not significantly correlated. Alternatively, compare the correlation strength between two groups of samples.
Tip: Manual calculation of complex formulas is usually unnecessary. The OA typically provides key statistics such as Z values or p values. Focus on whether the p value is below the significance level (for example, 0.05) and on the sign of the statistic indicating positive or negative correlation.
Rank-Based Hypothesis Testing
An applied core type that uses rank data to validate business hypotheses. Common in finance and tech company OAs and often combined with practical scenarios.
Typical format:
Scenario 1 (tech): Test whether the ranking of algorithm A’s recommendation accuracy is higher than algorithm B using the Jeffreys Hacker test.
Scenario 2 (finance): Test whether the ranks of fund returns in quarter 1 and quarter 2 differ, and determine whether to reject the hypothesis.
Key point: Clearly define the null hypothesis H0, usually stating no difference or no correlation, and the alternative hypothesis H1. Then interpret the test output (reject or accept H0) to draw business conclusions. Do not confuse H0 and H1, as interviewers often ask about this.
Handling Ties and Missing Data
An advanced type that evaluates how ranking logic adapts when data is imperfect. This is a practical challenge in the Jeffreys Hacker test.
Typical format: Given a dataset with duplicate values or missing entries, explain how to adjust rank calculations to avoid bias, or compare the impact of different missing data treatments, such as mean imputation or removing missing samples.
Practical tip: Recognize that ties reduce statistical power. When the proportion of ties exceeds 20%, it is recommended to use alternative nonparametric tests. Mentioning this demonstrates practical experience.
Comparative Rank Tests
Questions comparing multiple groups of data, commonly appearing in A/B tests or multi-solution selection scenarios.
Typical format: Given rank data for three algorithms, determine whether there is a significant overall difference using the Jeffreys Hacker test. If a difference exists, identify which two groups differ most significantly.
Note: Unlike pairwise comparisons, these questions focus on overall difference testing. Evaluate the overall significance first, then use post-hoc methods, such as Bonferroni correction, to identify specific group differences.
Jefferies HackerRank Preparation Strategies
Resources Used
HackerRank: Focus on the “Statistics” section under “Non-parametric Tests,” practicing basic rank assignment and correlation problems suitable for OA entry-level difficulty.
LeetCode: Filter by “Database” and “Statistics” tags to practice SQL for sorting and data preprocessing, as well as Python coding for hypothesis testing.
YouTube Channels: Watch video explanations for any problems where the solution process is unclear.
Practice and Time Management
Early Stage (1-2 days): Spend 30 minutes daily on HackerRank basics, starting with rank assignment rules, then correlation analysis, ensuring 100% accuracy on foundational problems.
Middle Stage (2-3 days): Spend 1 hour daily, half on LeetCode integrated problems, half on dissecting finance or algorithm-based hypothesis testing questions.
Final Stage (1 day): Simulate OA timing (40 minutes per session), focusing on quickly handling ties and missing values. Record mistakes only as “rule errors,” such as incorrect H0 setup or missing rank calculation steps.
What Worked for Me
Use a “scenario categorization” approach: organize all questions into four types—basic rank assignment, correlation analysis, hypothesis testing, and handling data anomalies. Memorize 2-3 core problem templates per category to avoid blind practice.
Keep code minimal: Use fixed Python templates for testing, such as preprocessing data, computing ranks, applying test functions, and outputting conclusions. This avoids thinking about structure during the test.
In the last three days before the test, review only “rule errors”: do not redo problems, just review previously recorded mistakes to consolidate high-frequency pitfalls in minimal time.
FAQ
How hard is the Jefferies Hackerrank test?
Basic rank assignment and correlation questions are easy to grasp, but the difficulty increases when handling ties, missing data, or business-related hypothesis testing. Success requires understanding both the rules and practical logic, not just memorizing formulas.
What programming languages can I use?
Python is the primary choice for the OA, with other languages rarely needed. Python offers flexibility in algorithmic scenarios. SQL is sometimes used only for simple data preprocessing.
Do I need to know finance for the technical section?
No prior financial knowledge is necessary. Most technical questions use general scenarios. However, for roles in finance companies, understanding basic concepts can help interpret questions faster. The core focus remains on the logic of rank testing.
See Also
2026 Nvidia HackerRank Test: Questions I Got and How I Passed
How I Cracked 2026 Citadel HackerRank Assesment Questions
My IBM 2026 HackerRank Assessment: Real Questions & Insights
My 2026 MathWorks HackerRank Assessment Questions & Solutions
Questions I Encountered in 2026 Goldman Sachs HackerRank Test

© Copyright 2025 Linkjob.ai - All Rights Reserved.