How I Mastered Databricks Coding Interview in 2026


I mastered my Databricks coding interview in 2026 by breaking down each stage and focusing on what mattered most—practice, feedback, and a resilient mindset. The process felt tough, especially with technical rounds leaning toward LeetCode hard problems and tricky optimizations.
To be honest, I used some tricks to cheat in my coding interview without being noticed. While hard work is certainly important, sometimes taking shortcuts can lead us to success by sheer luck.
I am really grateful to Linkjob AI for helping me pass my interview, which is why I’m sharing my Databricks coding interview experience here. Having an undetectable AI interview tool during the process indeed provided me with a significant edge.

Key Takeaways
Understand the interview process. Familiarize yourself with each stage, from recruiter calls to onsite interviews, to reduce anxiety and prepare effectively.
Practice with purpose. Focus on LeetCode hard-level problems and common data structures, such as Databricks new grad interview questions, to build confidence and improve problem-solving skills.
Pay sufficient attention to behavioral questions. Structure your answers to highlight your experiences and align with Databricks’ core values.
Seek feedback and engage in mock interviews. Practice with tools like Linkjob AI to refine your responses and improve communication skills.
An Overview of Databricks 2026 SWE Interview Process
The position I applied for is Databricks software engineer, and now I’ll walk you through the entire interview process. You may find more details in my other article: How I Landed Databricks 2026 SWE Interview and Received Offer.
Stage | Duration | Focus |
|---|---|---|
Recruiter Call | 30 minutes | Background, motivation, role overview, initial screening |
Technical Phone Screen | 1 hour | LeetCode-style coding, medium-hard algorithms, live coding |
Hiring Manager Call | 1 hour | Behavioral questions, experience deep dive, team fit |
Onsite | 4-5 hours | Coding, system design, concurrency, behavioral interviews |
Step 1: Recruiter Call (30 minutes)
I start with a 30-minute recruiter chat covering my background, role fit, and interest, while my profile is shared for early team matching.
Step 2: Technical Phone Screen (1 hour)
I complete a one-hour coding interview with LeetCode-style problems using an online IDE, focusing on algorithmic problem-solving and coding efficiency.
Step 3: Hiring Manager Call (1 hour)
I discuss my experience and project focus in a behavioral interview with the hiring manager to assess team alignment and role fit.
Step 4: Onsite (4-5 hours)
I go through multiple rounds including coding, concurrency, system design, and behavioral interviews tailored to role level and team specialization.
My Recent Databricks SWE Interview Experience in 2026—Real Coding Questions
I went through the full loop for a software engineer role at Databricks, and honestly, the coding bar felt pretty high. Most questions leaned toward LeetCode medium–hard, sometimes straight-up hard.
I’ll walk through exactly what I saw, especially the coding rounds, since that’s what really mattered.
Technical Phone Screen Coding Questions
This round was on CoderPad with a real engineer.
We jumped into coding almost immediately, barely any intro.
Coding Question 1: Grid BFS (Shortest Time + Cost)
I got a classic grid BFS problem, but with a twist.
Given a 2D grid with:
S= start,D= destinationNumbers = different “transport modes”
X= blocked
Each mode had different time and cost multipliers
Goal: find the best mode with:
minimum total time
if tie → minimum cost
At first it looked like standard BFS, but the tricky part was:
I had to run BFS once per mode
Then compare
(time, cost)across modesThe interviewer hinted I should avoid scanning the grid multiple times unnecessarily
I wrote a BFS using a queue and tracked visited nodes.
Then I looped through all modes and computed total time/cost.
The code was very runnable-heavy, like real production style.
Edge cases mattered a lot (blocked paths, unreachable destination, etc.).
Coding Question 2: Random Graph Connection (Follow-up round)
In a later phone round, I got something way more mathy.
Given N disconnected graphs
Add edges so the whole graph becomes connected
Return a set of edges uniformly sampled from all valid solutions
This one was tricky.
The key challenge wasn’t just connecting components, but making sure:
Every valid solution had equal probability
Not biased toward certain structures
I started with union-find to track components, then discussed how to randomize edge selection properly.
I didn’t fully finish the optimal version, but the interviewer gave hints and we worked through it together.
Whenever I get stuck on my coding interview questions, I turn to Linkjob AI for help. It is really useful, which can quickly generate code that meets the requirements and uses state-of-the-art AI models, such as Google: Gemini 3 Flash Preview.
Undetectable AI Coding Interview Copilot
Onsite Coding Questions
The onsite had multiple coding rounds, each for about 1 hour.
Coding Round 1: File System + Optimization
This one felt very “Databricks-style”.
Part 1
File system as a tree:
DirectoryNode→ childrenFileNode→ hasis_encrypted
Task: recursively count:
encrypted files
unencrypted files
Pretty straightforward DFS.
Part 2 (Real Challenge)
Two APIs:
encrypt_file(file)→ cost = T_req + T_fileencrypt_directory(dir)→ cost = T_req + N × T_file
Goal: minimize total encryption time
This turned into an optimization problem.
Key idea:
Batch encrypt when possible to reduce repeated
T_reqBut not always optimal depending on structure
I discussed trade-offs and used a recursive strategy to decide:
encrypt individually vs. encrypt directory
This round had a lot of whiteboard-style discussion + code.
Coding Round 2: Snapshot Iterator
This was one of the most interesting ones.
Design a set that supports:
add/remove
create iterator snapshot
Requirement:
future updates should NOT affect existing iterators
Naive solution:
Copy the whole set for every snapshot ❌ (too much space)
Better idea:
Versioning / persistent data structure
Store changes incrementally
Follow-up pushed hard on:
reducing memory usage
handling many snapshots efficiently
This felt very close to real system design + coding hybrid.
Coding Round 3: Concurrency (Thread-safe Design)
This round was tough.
I got something like:
implement a thread-safe LRU cache with TTL
We discussed:
locking strategies (coarse vs fine-grained)
race conditions
eviction policy with expiration
Follow-ups included:
how to reduce lock contention
how to scale to high QPS
This round was less about perfect code, more about correctness + design thinking.
Common Databricks Coding Question Types and Patterns
LeetCode Hard-Level Problems
From my experience, Databricks leans heavily toward harder-than-average LeetCode questions. It’s not just about getting something that works — I often had to optimize it under pressure, handle tricky edge cases, and explain why my approach was actually efficient. Brute force might get you started, but it won’t get you through.
Data Structures and Algorithms
Most coding rounds were centered around core DS&A, especially graphs, trees, and traversal problems like BFS/DFS. What stood out was how quickly a “standard” problem could turn into something more complex with added constraints. I had to constantly think about time/space trade-offs and refine my solution on the fly.
SQL and Data Engineering
Even for software roles, there’s some overlap with data engineering concepts. I didn’t get a pure SQL round, but I was expected to think about large-scale data processing, efficiency, and how systems handle real-world data. Knowing how data flows and gets transformed is definitely a plus.
System Design Challenges
What surprised me was how often coding questions drifted into system design discussions. I’d finish coding, and then the interviewer would ask how this scales, how to make it thread-safe, or how to reduce memory usage. It felt like they were testing not just coding ability, but how I think as an engineer building real systems.
Preparation Strategies for Databricks Coding Interview
When I started preparing for the Databricks coding interview, I broke my prep into 4 main areas: study resources, mock interviews, time management, and progress tracking. Let me walk you through what worked best for me.
Study Resources and Practice
I focused on high-quality materials closely aligned with Databricks interview topics. I combined books, coding platforms, and official Databricks resources to build a solid foundation.
Among the 6 best AI coding interview assistants, I highly recommend Linkjob AI, which serves as a real-time AI interview assistant during practice sessions. It helps simulate Databricks-style interviews, offers a comprehensive collection of frequently asked questions, and enables personalized mock interviews based on my skill level.
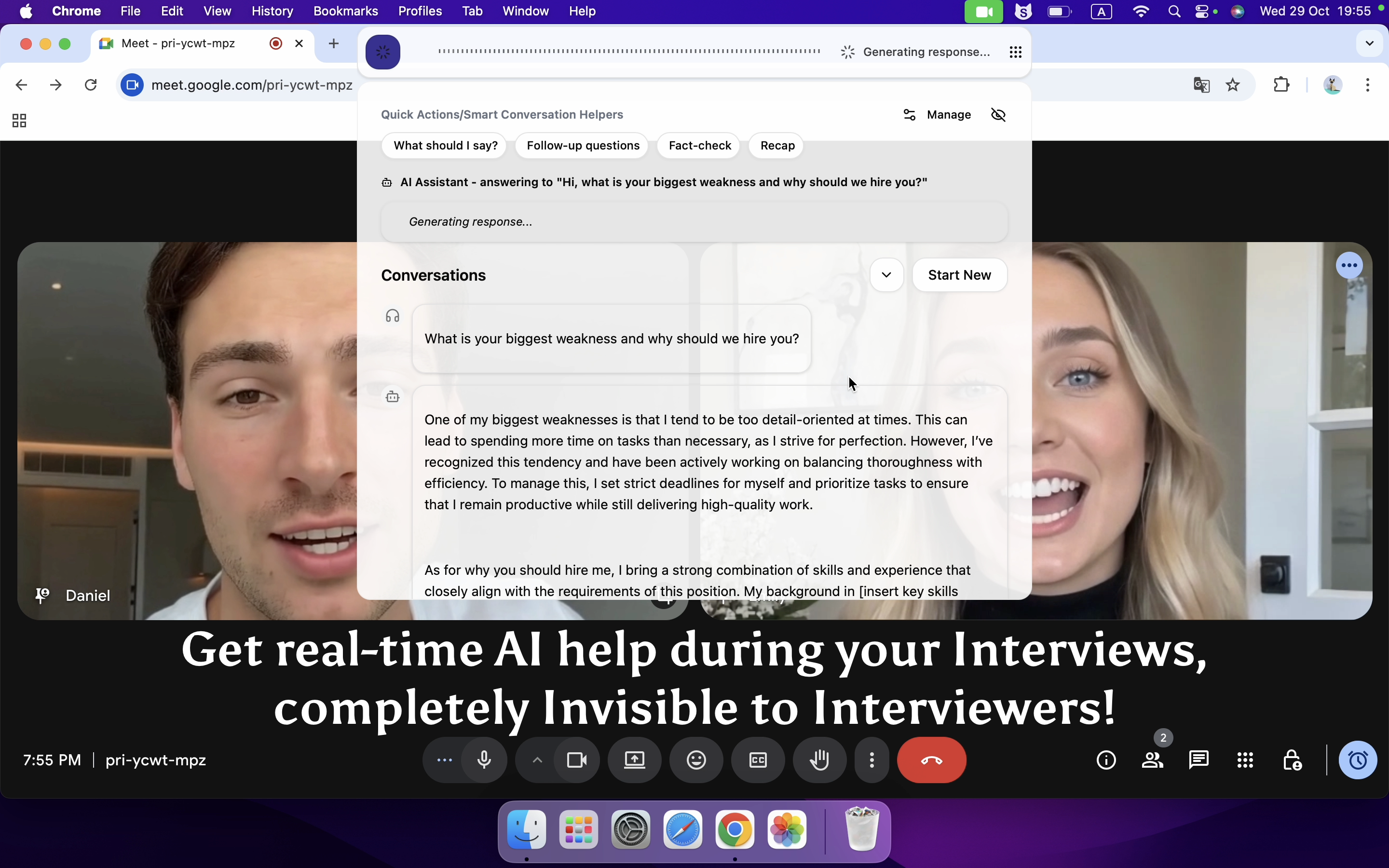
Real-time AI Interview Assistant
To begin with, I solidified my programming fundamentals. I read Learning Spark and Designing Data-Intensive Applications to understand distributed systems, and also used Databricks Academy and official documentation to get familiar with their platform and tools. Practicing SQL daily helped me recognize common query patterns more quickly.
My approach was always to combine theory with practice. After learning a concept, I immediately applied it to related coding problems to reinforce understanding.
Mock Interviews and Feedback
Mock interviews were one of the most important parts of my preparation. I practiced with peers, as well as Linkjob AI’s AI mock interview feature, which simulates real interview pressure and provides instant feedback on my answers.
I focused on solving SQL problems regularly, practicing Spark-related coding questions, and working through scenario-based problems that reflect real-world use cases. I also practiced explaining my solutions in simple English, which significantly improved my communication clarity.
After each mock interview, I actively collected feedback and worked on my weak areas. This iterative process helped me improve both accuracy and confidence over time.
Time Management Tips
I followed a structured daily study plan and treated preparation like a real job. I used timed sessions to simulate interview conditions and improve my speed under pressure.
I prioritized high-frequency topics such as data structures, algorithms, SQL, and system design. I also reviewed Spark concepts regularly to reinforce distributed computing fundamentals. If Databricks‘ question bank is no longer sufficient for my practice, I will look for interview questions from other companies, such as OpenAI coding interview question bank. Breaking study sessions into focused blocks with short breaks helped me avoid burnout and stay consistent.
Over time, I focused not just on solving problems, but on solving them efficiently and clearly explaining my thought process.
Progress Tracking
Tracking my progress helped me stay motivated throughout the preparation process. I kept a simple log of solved problems, mistakes, and mock interview performance.
I also used Linkjob AI’s AI-driven feedback system to identify gaps in my preparation and adjust my study plan accordingly. This helped me quickly spot weak areas and improve faster than traditional self-review methods.
Each week, I reviewed my progress, refined my study plan, and focused more on areas where I struggled. I also made sure to celebrate small wins, such as solving difficult problems or improving mock interview performance, which kept me motivated throughout the process.
Databricks Behavioral and System Design Rounds
STAR Method for Behavioral Questions
Component | Description |
|---|---|
Situation | I briefly explain the context of the scenario. |
Task | I define the objective or problem I faced. |
Action | I describe the steps I took to solve it. |
Result | I highlight the outcome and what I learned. |
Collaboration and Leadership
Competency | Description |
|---|---|
Collaboration | I leverage diverse skills and viewpoints in a team, integrating solutions that meet broad needs. |
Communication | I use tools and strategies to synchronize work and anticipate challenges. |
Adaptability | I adjust my approach to bridge gaps and keep a user-first mindset. |
Problem-solving | I provide examples of overcoming breakdowns and recalibrating for better outcomes. |
System Design Evaluation
Criteria | Description |
|---|---|
Problem Structuring | I clarify requirements and break down complex problems. |
Scalability | I explain how my design adapts to large workloads. |
Trade-offs | I discuss latency, throughput, and cost decisions. |
Communication Skills | I explain concepts clearly and justify my choices. |
Diagramming Skills | I create diagrams to illustrate architecture and flows. |
Mindset and Success Tips for Databricks Coding Interview
Staying Motivated
Staying motivated during my Databricks prep wasn’t easy. I hit doubts often, but feedback from experienced candidates helped a lot. Practicing with someone who had been through the process gave me direction. I set small weekly goals and celebrated progress—whether solving a tough SQL problem or finishing a mock interview.
Handling Feedback and Rejection
Feedback and rejection were tough at first, but I learned to use them to improve. I focused on strengthening SQL, Python, and PySpark fundamentals, especially joins and optimization. I reviewed weak areas like window functions and prepared for real scenarios like large datasets, pipeline failures, and cost efficiency.
Building Confidence
Practice data structures and algorithms (DSA) consistently.
Write clean and structured code.
Engage in mock interviews on platforms like Linkjob AI with real Databricks questions.
Targeted Practice Benefits | Why It Matters |
|---|---|
Real-world problem-solving | Builds skills for Databricks-style challenges |
Mock interviews | Boosts communication and confidence |
Community resources and labs | Offers hands-on, relevant practice |
FAQ
How did I choose which topics to focus on first?
I started with the most common topics from recent Databricks interviews. I made a list of data structures, algorithms, and SQL concepts. I tackled the hardest ones early, then circled back to review basics.
What should I do if I get stuck on a Databricks coding problem?
I pause and break the problem into smaller steps, and then turn to Linkjob.ai for help. But I won’t just copy the AI-generated answers. I’ll combine them with what I’ve learned and rephrase them in my own words.
Do I need to know Spark or PySpark for the Databricks coding interview?
Yes! I reviewed Spark basics and practiced PySpark coding. I learned how to build simple ETL pipelines and explain my choices. Knowing Spark concepts helped me stand out in data engineering rounds.
See Also
Anthropic Coding Interview: My 2026 Question Bank Collection
My 2026 Databricks System Design Interview: Tough Qs Solved
My Firsthand Experience With Amazon's 2026 Coding Interview
