How I Landed Databricks Software Engineer Interview and Received Offer in 2026


I recently successfully secured an interview for a 2026 software engineer position at Databricks. I started by digging deep into Databricks’ culture and technology, and made sure my resume and LinkedIn showed real results. I also reached out to current employees and joined tech events. Of course, the most important thing is that I practiced coding challenges and focused on expressing myself clearly.
However, I have to admit that hard work alone isn’t enough for me to land an interview for a Databricks software engineer position. I also need to master some lesser-known techniques. To be honest, I used a real-time AI interview assistant to help me figure out part of my answers.
I am really grateful to Linkjob AI for helping me pass my interview, which is why I’m sharing my entire Databricks software engineer interview experience here. Having an undetectable AI interview tool during the process indeed provided me with a significant edge.

Key Takeaways
Tailor your resume and LinkedIn profile to match job descriptions. Use keywords and highlight relevant skills to stand out.
Quantify your achievements with metrics. Numbers demonstrate your impact and catch recruiters’ attention.
Network with current employees and seek referrals. Personal connections can significantly increase your chances of landing an interview.
Practice coding and system design regularly. Linkjob AI Mock interviews help build confidence and improve your problem-solving skills.
Stay persistent and learn from rejections. Each setback is an opportunity to grow and refine your approach.
My Recent Databricks SWE Interview Experience—Latest Real Questions in 2026
Landing a Software Engineer role at Databricks was a challenging but rewarding experience. From the recruiter call to the onsite interviews, each stage tested my skills and preparation, especially the questions from Databricks coding interview. Here‘s a breakdown of how the entire process went.
Stage 1. Recruiter Call (30 minutes)
The first stage was a Recruiter Call. This was mainly an introductory conversation where I talked about my background, experience, and why I was interested in the role at Databricks. The recruiter also gave me an overview of the interview process, including timelines and expectations. It was a low-pressure call, but I did my best to convey my enthusiasm for the role and how my experience aligned with what Databricks was looking for.
Stage 2. Technical Phone Screen (1 hour)
The Technical Phone Screen was the next stage and it lasted about an hour. I was interviewed using CoderPad, where I had to write working code in real time. Here’s how it went:
Coding Question 1: BFS for Shortest Time/Cost
I was given a 2D grid and had to find the shortest time and cost from a starting point S to a destination D. The grid contained different transport modes, each with a different time and cost multiplier.
The challenge was to run BFS (Breadth-First Search) once for each mode and calculate the total time and cost, then select the best mode.
The interviewer asked me to optimize the solution and avoid scanning the grid multiple times. I implemented BFS using a queue and tracked visited nodes.
This question tested my ability to optimize algorithms and handle edge cases.
Coding Question 2: Random Graph Edge Addition
I was also asked to implement a function that would uniformly sample edges to add between disconnected graphs so that they would become connected. The trick was to ensure the edges were selected uniformly from all possible solutions.
This involved using union-find (disjoint-set) to track connected components and carefully selecting edges without bias.
The interviewer guided me through the process and asked about the complexities of the solution.
Whenever I get stuck on my coding interview questions, I turn to Linkjob AI for help. It is really useful, which can quickly generate code that meets the requirements and uses state-of-the-art AI models, such as Google: Gemini 3 Flash Preview.
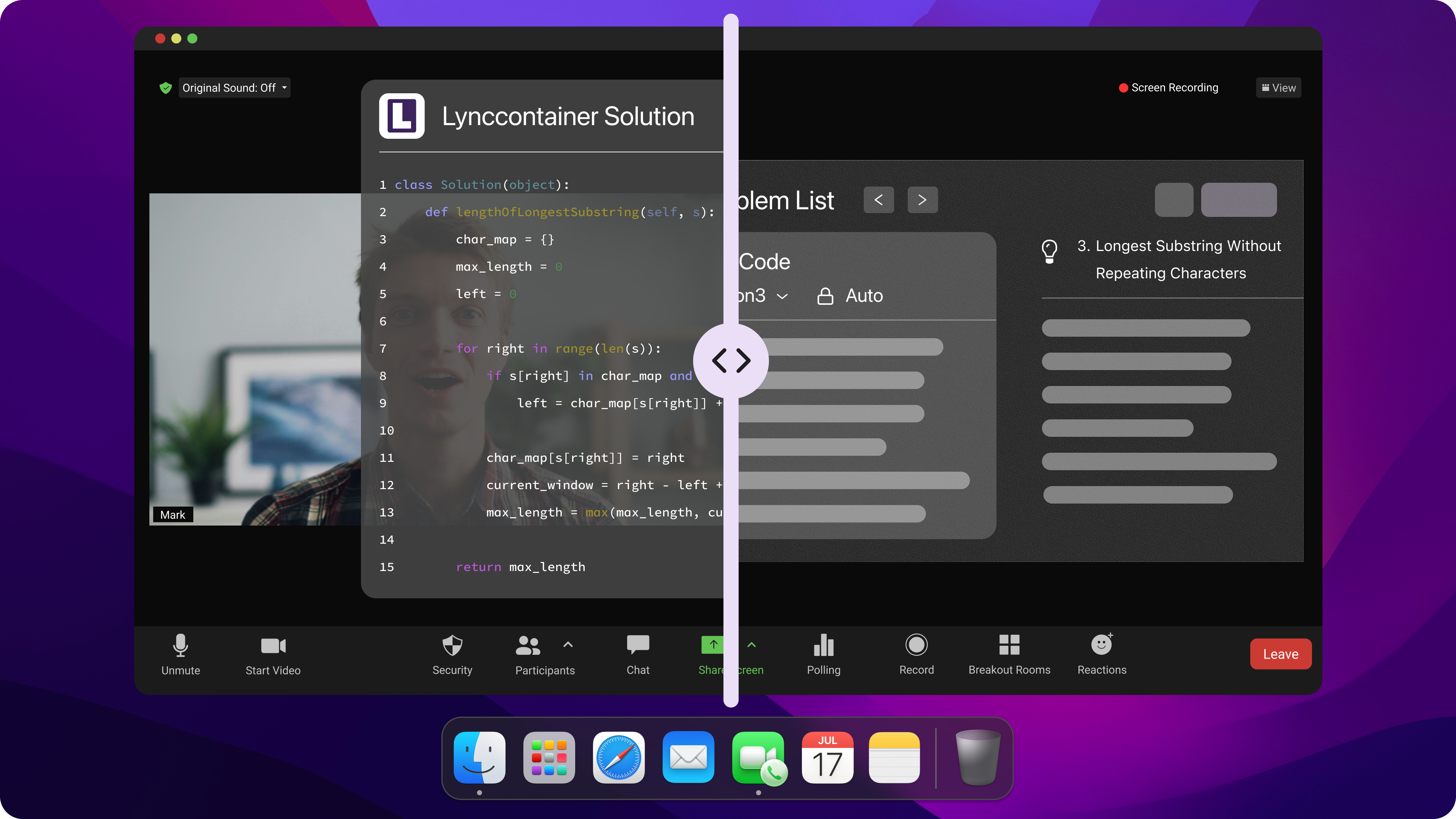
Undetectable AI Coding Interview Copilot
Stage 3. Hiring Manager Call (1 hour)
The next stage was a Hiring Manager Call, where I spoke with the manager for an hour. This call was more focused on my background, problem-solving approach, and alignment with Databricks culture. We also discussed:
My past projects and how I would apply that experience to the Databricks environment.
Behavioral questions focused on teamwork, problem-solving, and handling conflict in engineering teams.
This call gave me a deeper understanding of the role and how Databricks operates.
Stage 4. Onsite (4-5 hours)
The Onsite Interviews were intense and lasted about 4-5 hours, spread across multiple rounds. Here’s a breakdown of the rounds:
Coding Round 1: File System Encryption
I was given a tree structure representing a file system with directories and files.
I had to recursively count how many files were encrypted and unencrypted.
Then, I was asked to implement a function to encrypt all unencrypted files. The catch was optimizing the time it took to encrypt files, given different constraints.
This round tested my understanding of recursive algorithms and optimization.
Coding Round 2: Snapshot Iterator
Next, I worked on a problem involving a set that supported creating snapshot iterators.
I had to implement an iterator that would give a snapshot of the current set, but adding/removing elements in the set should not affect existing iterators.
The interviewer asked me to optimize the space complexity of the solution, especially when dealing with multiple snapshots.
This problem required me to think about versioning and how to handle incremental changes efficiently.
Concurrency Round: Thread-safe LRU Cache
This was one of the most challenging rounds. I had to implement a thread-safe LRU cache with a TTL (Time to Live) mechanism.
The interviewer asked me to handle concurrent access and ensure thread-safety while performing eviction based on the TTL.
We discussed locking strategies and how to ensure the cache could scale under high load.
This round tested my knowledge of multithreading, caching strategies, and race condition handling.
System Design Round: Distributed Rate Limiter
In the System Design round, I was asked to design a distributed rate limiter using a sliding window approach.
We discussed how to scale the system to handle millions of requests per second while ensuring fairness across clients.
I also had to consider fault tolerance, network latency, and how to handle request bursts.
This round tested my system design skills and my ability to think about scalability in distributed systems.
If you‘re looking for more Databricks-style questions, I recommend you read Databricks new grad interview questions.
Resume And Profile Optimization
Databricks Software Engineer Interview Skills
When I started preparing for the databricks software engineer interview, I focused on the skills that Databricks values most. I made a table to track my progress and highlight these skills on my resume and LinkedIn:
Skill/Qualification | Description |
|---|---|
Programming Languages | Node.js, Java, Python, Scala, C#, C++, Go |
Cloud Technologies | AWS, Azure, GCP, Docker, Kubernetes |
System Design | SaaS platforms, Service-Oriented Architectures |
JavaScript Frameworks | React, Angular, VueJs, Ember |
I also practiced algorithmic problem-solving and worked on distributed systems, using real questions from other companies like OpenAI coding interview question bank. I made sure to mention these skills in my profile, using keywords from Databricks job postings.
Project Highlights And Achievements
I learned that recruiters at Databricks look for real impact. So, I described my projects using the Action → Tool → Impact format. For example, I wrote about building a scalable ETL pipeline with Apache Spark that reduced processing time by 40%. I included metrics like model accuracy and cost savings. On LinkedIn, I detailed achievements, such as managing clusters and designing efficient pipelines. I kept my project descriptions clear and focused on results.
Tip: Quantify your achievements. Numbers catch a recruiter’s eye and show your value.
Using Keywords And Metrics
I tailored my resume and LinkedIn to match the databricks software engineer interview requirements. I used keywords from job descriptions, like “data engineering,” “Apache Spark,” and “cloud computing.” I added a summary at the top of my resume that highlighted my achievements and business impact. I tracked the keywords I used and made sure they matched the role. I also included quantifiable metrics, such as reducing latency by 25% or securing $2M in time savings. This approach helped my resume stand out in applicant tracking systems and to recruiters.
Databricks SWE Application Strategy
Applying For Databricks Software Engineer Interview
I started my application process by researching the best time to apply. I noticed that Databricks posts new roles at the start of each quarter, so I set reminders to check their careers page every week. I also used job boards like LinkedIn and Wellfound. I made sure to apply as soon as I saw a new opening.
The average time from application to interview offer is usually two to five weeks. I stayed patient and kept track of my applications in a spreadsheet. Most decisions came just days after the onsite interview.
Customizing Applications
I learned that a generic application rarely gets noticed. I always tailored my resume and cover letter for each Databricks software engineer interview. Here’s what worked for me:
I matched my resume to the job requirements listed in the posting, in order to get feedback from recruiters.
I showcased the programming problems I practiced on Leetcode in my coding samples.
I reviewed Databricks’ values to show cultural fit in my cover letter.
I wrote about my past projects and the challenges I solved.
I made sure to write clean and efficient code in my coding samples. I also prepared to talk about my projects and how I overcame obstacles.
Leveraging Referrals
Referrals made a huge difference in my application process. I reached out to Databricks employees on LinkedIn and asked for advice. Sometimes, they offered to refer me. This helped speed up the process and increased my chances of getting an interview. Here’s how referrals helped:
Evidence Point | Description |
|---|---|
Recruitment Duration | Referrals significantly reduce the time taken to hire candidates at Databricks. |
Screening Success | Candidates referred by employees have higher chances of passing initial screenings due to prior collaboration and trust. |
Scheduling Efficiency | Warm introductions from referrals lead to quicker scheduling of interviews and faster decision-making. |
If you want to boost your chances, don’t hesitate to ask for a referral. A warm introduction can open doors that a cold application cannot.
Networking and Outreach with Databricks
Connecting With Databricks Employees
I knew connecting with Databricks employees would help, so I reached out on LinkedIn. I sent personalized messages, asking about their work and projects. I kept it short, respectful, and focused on building relationships. Over time, I learned about the company‘s values, like collaboration and growth.
Tip: Don’t just ask for referrals—start real conversations and show interest.
Attending Databricks Events And Meetups
I wanted to meet Databricks folks in person, so I attended the Databricks Bristol Meetup. Hosted by iO Associates, it brought together engineers, recruiters, and data pros. I joined discussions on real-world challenges, got direct access to recruiters, and expanded my network. Plus, I picked up insights on the latest tools and trends in data engineering.
Engaging On Professional Platforms
On LinkedIn, I boosted my visibility by following Databricks and engaging with their posts. By commenting on articles about data and cloud tech, I joined the conversation and got noticed. Sharing my own projects and tailoring my profile to highlight relevant experience helped too. Connecting with employees not only gave me valuable insights but also opened doors for potential referrals.
Note: Databricks values communication and solving business problems, not just technical skills.
Databricks SWE Interview Preparation
Databricks Interview Process Overview
I wanted to know exactly what to expect from the Databricks software engineer interview process. I learned that Databricks uses a structured approach, which helps candidates prepare better. Here’s how the process usually goes:
Stage | Duration | Focus |
|---|---|---|
Recruiter Call | 30 minutes | Background, motivation, role overview, initial screening |
Technical Phone Screen | 1 hour | LeetCode-style coding, medium-hard algorithms, live coding |
Hiring Manager Call | 1 hour | Behavioral questions, experience deep dive, team fit |
Onsite | 4-5 hours | Coding, system design, concurrency, behavioral interviews |
Step 1: Recruiter Call (30 minutes)
I start with a 30-minute recruiter chat covering my background, role fit, and interest, while my profile is shared for early team matching.
Step 2: Technical Phone Screen (1 hour)
I complete a one-hour coding interview with LeetCode-style problems using an online IDE, focusing on algorithmic problem-solving and coding efficiency.
Step 3: Hiring Manager Call (1 hour)
I discuss my experience and project focus in a behavioral interview with the hiring manager to assess team alignment and role fit.
Step 4: Onsite (4-5 hours)
I go through multiple rounds including coding, concurrency, system design, and behavioral interviews tailored to role level and team specialization.

The whole process can take up to eight weeks. Databricks recruiters tell candidates about this timeline early on. I stayed patient and kept track of each step.
Databricks Technical And Behavioral Questions
For the technical rounds, I focused on coding challenges (LeetCode hard problems) and system design questions like building a data pipeline. I also practiced big data, SQL, and cloud tech, making sure I could explain my experience with Spark and Python. It was key to show my thought process, not just the final answer.
Behavioral questions were about teamwork, conflict resolution, and past experiences. I used the STAR method to structure my answers, focusing on real examples—like how I debugged ETL jobs, designed real-time systems, and handled tricky situations with teammates.
Databricks Practice And Mock Interviews
I knew that practicing was the key to success in the Databricks software engineer interview. I set up mock interviews with friends and used online platforms like Linkjob AI. Mock interviews helped me get comfortable with coding under pressure and answering behavioral questions.
Focus Areas | Key Topics |
|---|---|
Big Data, SQL & Coding | Project experience, SQL challenges, dataset joins, Python optimization, Spark performance |
Advanced Big Data + Real-Time Processing | Data pipeline strategies, ETL job debugging, cloud services, Kafka use cases |
System Design & Architecture | Real-time system design, data lake construction, recommendation engine design |
Among the 6 best AI coding interview assistants, I highly recommend Linkjob AI, which serves as a real-time AI interview assistant during practice sessions. It helps simulate Databricks-style interviews, offers a comprehensive collection of frequently asked questions, and enables personalized mock interviews based on my skill level.
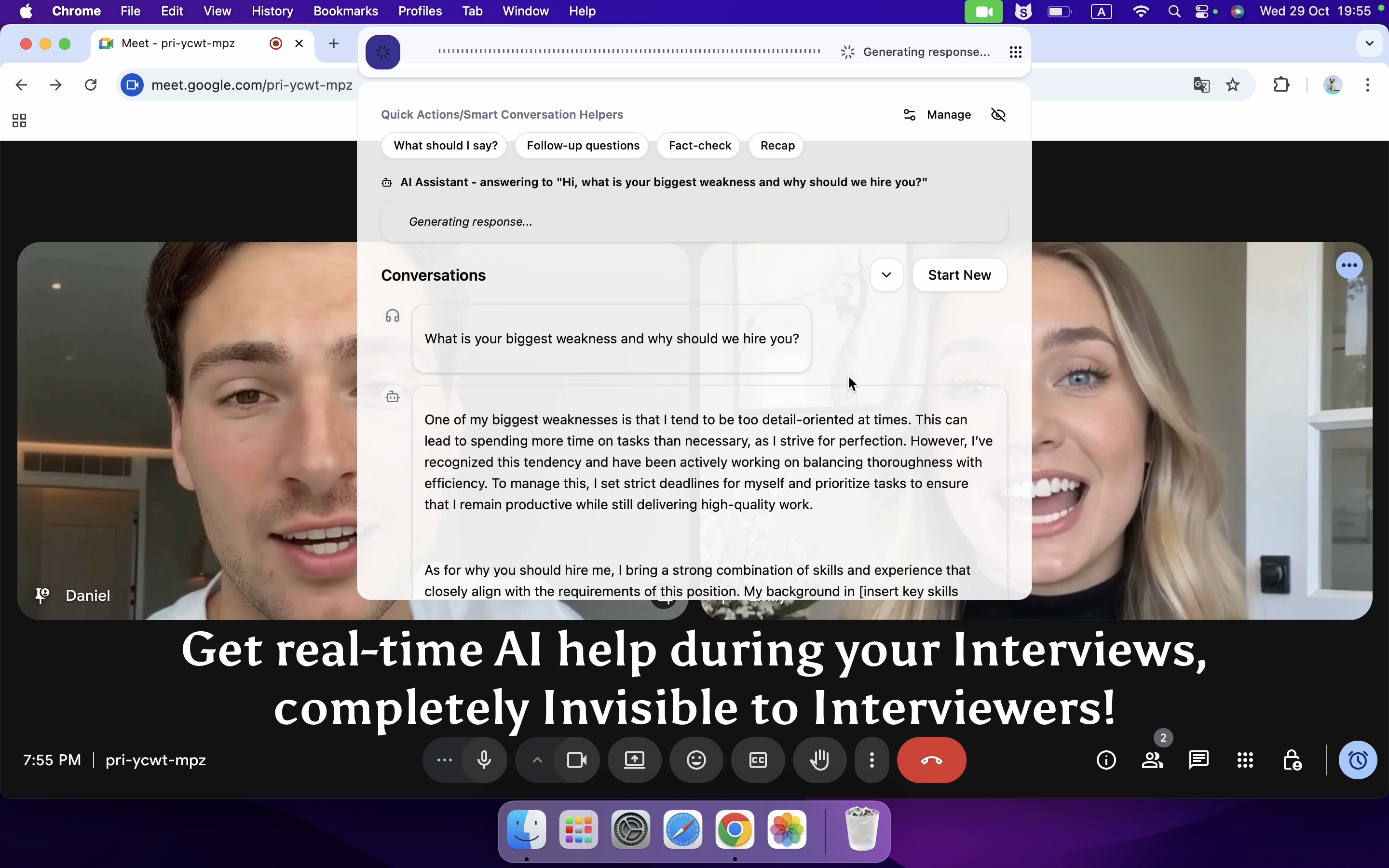
Real-time AI Interview Assistant
Overcoming Challenges of Databricks SWE Interview
Handling Rejections
I faced a lot of rejections during my Databricks journey, but I treated them as learning experiences. Instead of procrastinating, I applied right away and made a solid plan for technical prep—data structures, algorithms, SQL, and PySpark. I used mock interviews to find knowledge gaps and kept improving. Every rejection helped me grow, and persistence eventually paid off.
Staying Motivated
Staying motivated wasn’t easy during the tough Databricks interview process. I spent hours on coding and system design, tackling tricky problems. Sometimes it felt overwhelming, but I kept reminding myself of my goal. Focusing on progress and celebrating small wins—like solving a tough LeetCode problem—helped. Connecting with other candidates kept me positive.
Tip: Celebrate small victories and stay focused on your goal. Motivation grows when you see progress.
Adapting Strategies
As I went through the process, I adapted my strategies. I practiced coding daily, worked on system design trade-offs, and focused on teamwork for behavioral rounds. If something didn’t work, I changed it—whether it was trying new study methods or asking for feedback. Flexibility helped me stay sharp and ready for any challenge.
The key was to keep improving and stay persistent. Top companies want problem solvers who can communicate clearly. I kept growing, learning from setbacks, and testing my solutions.
FAQ
How did I prepare for Databricks SWE coding interviews?
I practiced daily on Linkjob AI. I focused on data structures, algorithms, and SQL. AI Mock interviews helped me get comfortable with timed coding. I reviewed my mistakes and learned from each session.
Linkjob AI offers many of the most advanced AI models currently available on the market. I can choose the one that best suits my needs,such as Google: Gemini 3 Flash Preview.
What projects helped my Databricks SWE application stand out?
I built scalable ETL pipelines using Apache Spark, and managed cloud clusters and optimized data processing. I always included metrics, like reducing processing time or saving costs. Recruiters noticed real impact.
How did I find Databricks SWE referrals?
I connected with Databricks employees on LinkedIn and started conversations about their work. Sometimes, I asked for advice. If the chat went well, I politely requested a referral. A warm introduction made a big difference.
What resources did I use for Databricks system design prep?
I read “Designing Data-Intensive Applications”, watched YouTube videos on system architecture, and drew diagrams for practice. I also joined online forums to discuss design trade-offs. Real-world projects gave me hands-on experience.
See Also
Anthropic Coding Interview: My 2026 Question Bank Collection
My 2026 Databricks System Design Interview: Tough Qs Solved
My Firsthand Experience With Amazon's 2026 Coding Interview
